
Le bon fonctionnement du traitement data en production
Question : Comment s'assurer que les traitements en production fonctionnent correctement et soient informés en cas d'erreur ?
Contexte : Pour garantir la fiabilité des traitements en production et être rapidement informé en cas d'incident, une vérification minutieuse s'impose : cela consiste à s'assurer que tous les scénarios de transformation de données ou d'entraînement de modèles de Machine Learning, sont équipés de triggers et de reporters.
triggers et reporters
Les triggers permettent de configurer le déclenchement précis d'un scénario, tandis que les reporters permettent l'envoi immédiat de mails ou de notifications, intégrant des informations pertinentes quant au statut du scénario (i. e. métriques, fichiers Excel, ...).
Un plugin pour faciliter l’obtention des informations dans une table
Réponse : Nous avons donc développé un plugin facilitant l'obtention rapide de ces informations essentielles directement dans une table (projet dans lequel se trouve le scénario, est-il actif, les triggers ou les reporters sont-ils renseignés ?). Cette solution vise à optimiser la surveillance des processus en production et à renforcer la réactivité des équipes face aux éventuelles anomalies.


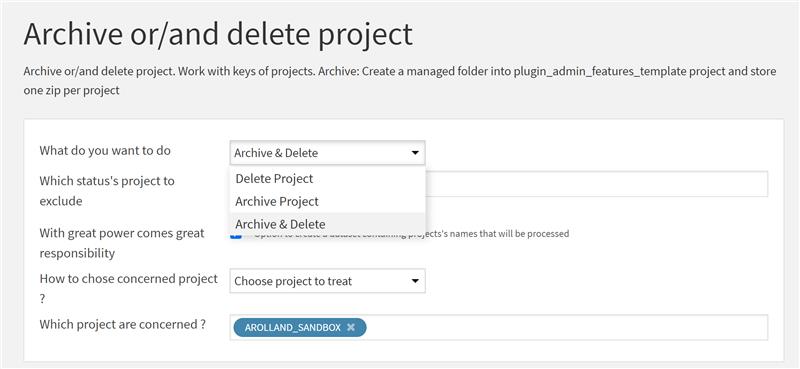
Stratégies de gestion des projets obsolètes avec la plateforme Dataiku
Question : Comment s'assurer que la plateforme Dataiku ne contienne que des projets utilisés, utiles ou industrialisés?
Contexte : Dans le but de maintenir la pérennité et la performance de la plateforme Dataiku, tout en limitant la présence de projets non essentiels, il est impératif d'adopter des stratégies avancées de nettoyage. Une approche proactive consiste à archiver les projets, en les compressant au format ZIP pour préserver l'intégrité de l'information qu'ils contiennent. Ces projets peuvent s'avérer très lourds pour la plateforme, notamment pour les projets d'Intelligence Artificielle qui embarquent des modèles de Machine Learning et les données nécessaires à leur entraînement. La suppression de ces projets devient, à terme, une étape nécessaire pour libérer de l'espace sur l'instance Dataiku.
Réponse : Nous avons alors développé un plugin permettant de réaliser de manière automatique ces étapes d'archivage et de suppression des projets. Dans l'outil, l'identification de ces projets peut se faire selon divers critères, offrant ainsi une flexibilité optimale :
ol  {margin-bottom:0in;margin-top:0in;}ul {margin-bottom:0in;margin-top:0in;}li {margin-top:.0in;margin-bottom:8pt;}ol.scriptor-listCounterResetlist!list-67b14953-2e11-4bba-84d0-2c5dd16e07d30 {counter-reset: section;}ol.scriptor-listCounterlist!list-67b14953-2e11-4bba-84d0-2c5dd16e07d30 {list-style-type:bullet;}li.listItemlist!list-67b14953-2e11-4bba-84d0-2c5dd16e07d30::before {counter-increment: section;content: none; display: inline-block;}
Sélection par le statut ou le tag du projet
- La sélection par le statut ou le tag du projet permet une gestion basée sur l'état actuel de chaque projet.
Sélection par mots-clés
- La sélection par mots-clés permet une approche ciblée basée sur des critères textuels.
Sélection précise des projets
- La sélection précise des projets offre une granularité maximale pour un contrôle personnalisé.
Cette approche garantit une maintenance proactive de la plateforme, assurant son bon fonctionnement, tout en éliminant les projets superflus et obsolètes.
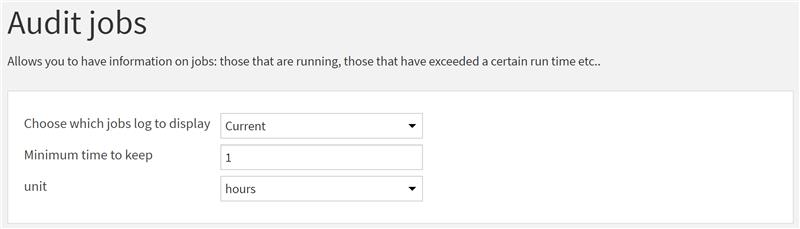
Monitoring et alerting des jobs prolongés des tâches Dataiku
Question : Comment monitorer et être alerté en cas de temps d'exécution trop long de tâches Dataiku ?
Contexte : Lorsque beaucoup de jobs (tâches) sont exécutés au sein d'un projet, les utilisateurs peuvent perdre la trace des plus anciens, même s'ils sont toujours en cours d'exécution. Il arrive aussi que certains jobs s'exécutent pendant une durée trop longue par rapport au besoin initial. Il convient alors de monitorer ces jobs.
Plugin listant les jobs déjà terminés
Réponse : Afin d'assurer une supervision proactive des jobs en cours d'exécution sur la plateforme, nous avons élaboré un plugin qui offre la possibilité de lister les jobs déjà terminés ayant dépassé une durée donnée (pour analyse), ou encore de répertorier tous les jobs en cours d'exécution depuis une certaine durée.
Cette fonctionnalité est essentielle pour prendre des mesures immédiates en cas d'incident non détecté au cours de l'exécution d'un job.
Audit approfondi des jobs
Par ailleurs, la seconde option, permettant de lister les jobs trop longs, offre la possibilité de réaliser un audit approfondi des jobs et des projets associés. Cet audit permet par exemple d'évaluer et de contrôler les coûts potentiellement engendrés. Cela en fait un outil indispensable pour optimiser la gestion opérationnelle et économique de la plateforme Dataiku.

Viabilité d'un projet Dataiku et correction en cas d'erreur
Question : Comment vérifier que la suppression d'un composant n'impactera pas la viabilité d'un projet ?
Suppression ou blocage
Contexte : La suppression d'un dataset ou d'une recette de transformation peuvent parfois entraîner des complications majeures. Celles-ci se traduisent par le blocage de l'action de suppression du projet, l'impossibilité de créer des bundles (snapshot du projet à instant précis) associés ou même la paralysie d'un projet dans sa globalité.

Erreurs et problèmes critiques
Le type d'erreur ci-dessus ne permet pas d'identifier l'élément bloquant l'enregistrement de toute évolution au sein du projet.
Réponse : Pour résoudre ce problème critique, nous avons développé un plugin permettant de parcourir tous les projets de l'instance Dataiku, listant ainsi tous les reliquats qui devront être corrigés afin d'assurer le bon fonctionnement d'un projet.
Gestion des utilisateurs dans les scénarios Dataiku
Question : Comment garantir la viabilité de l'exécution des tâches automatisées en fonction des droits utilisateurs ?
Contexte : Assurer la conformité des exécutions de scénarios (ordonnanceurs) avec les utilisateurs appropriés constitue un aspect critique du bon fonctionnement de la plateforme et des projets en production. C'est cet utilisateur qui fera hériter de ses droits à l'ensemble des tâches exécutées par le scénario. En cas de droits utilisateur limités, d'utilisateurs qui quittent l'entreprise, de création d'un utilisateur générique ou de modifications des droits associés, il devient fastidieux d'effectuer massivement des adaptations.
Réponse : C'est dans cette perspective que nous avons mis au point un plugin capable de parcourir tout ou partie des projets, afin de comparer l'utilisateur actuellement désigné pour l'exécution des scénarios et celui souhaité. Cela permet de réaliser une modification globale rapide et efficace.
Deux options distinctes sont offertes :
Recensement des écarts
- La première consiste en un recensement des écarts entre l'utilisateur actuellement utilisé pour exécuter le scénario et celui que l'on souhaite désormais utiliser,
Modifications dans les scénarios
- La deuxième propose des modifications directement dans les scénarios pour assurer l'affectation du bon utilisateur de manière rapide et efficace.

Utilisation optimale des moteurs d'exécution
Question : Comment s'assurer que les transformations dans Dataiku soient lancées avec le moteur d'exécution optimal ?
Veiller à l'adéquation entre le moteur d'exécution utilisé et la stack technologique
Contexte : Afin de maximiser l'efficacité des flux au sein de Dataiku, il est impératif de veiller à l'adéquation entre le moteur d'exécution utilisé et la stack technologique mise en place.
Une performance maximale des transformations et un usage
En effet, certains moteurs sont plus adaptés selon le cas d'usage. Cette vérification permet une performance maximale des transformations et un usage évitant toutes complications.
Réponse : Notre solution repose sur un plugin conçu pour répertorier de manière exhaustive toutes les recettes de l'instance Dataiku, en précisant leur type ainsi que le moteur actuellement employé. Ce processus offre aux développeurs une visibilité complète sur l'état des recettes, leur permettant d'ajuster et de réaligner ces dernières en cas d'incohérence. Grâce à cette approche, nous assurons une exécution optimale des tâches, contribuant ainsi à la performance globale des flux de données.

Optimisez l'espace de stockage de votre instance Dataiku
Question : Comment déterminer les tailles de tous les jeux de données téléchargés sur l'instance Dataiku, y compris ceux stockés sous forme de fichiers ?
Contexte : La surveillance et la maintenance proactive de la plateforme Dataiku nécessitent la collecte d'informations précises sur les dimensions des jeux de données qui y sont stockés. Cela inclut les jeux de données de type fichier tels que HDFS (Hadoop Distributed File System) ou GCS (Google Cloud Storage).
Plugin qui génère une liste de jeux de données
Réponse : Pour répondre à cette exigence, nous avons développé un plugin conçu pour explorer de manière exhaustive l'ensemble des projets hébergés sur l'instance Dataiku. Ce plugin génère une liste de tous les jeux de données associés à ces projets, ainsi que des informations détaillées sur leurs tailles respectives.
Gestion efficace des ressources et optimisation de l’espace de stockage sur l’instance Dataiku
En fournissant une vue précise de l'espace de stockage utilisé par chaque jeu de données, notre plugin permet une gestion efficace des ressources et une optimisation de l'espace de stockage sur l'instance Dataiku.
Libérer de l'espace et améliorer les performances globales de l'instance Dataiku
Les équipes chargées de la gestion de la plateforme peuvent ainsi identifier les jeux de données les plus volumineux et prendre les mesures nécessaires pour optimiser leur stockage, libérer de l'espace et améliorer les performances globales de l'instance Dataiku.

Une approche pour éviter les tables fantômes
Question : Comment s'assurer de la maintenance et de la propreté de sa base de données avec Dataiku ?
La propreté d'une base de données se traduit notamment par la suppression d'une table lorsque son usage n'est plus avéré.
Contexte : Lorsque l'on couple Dataiku avec une couche technologique SQL, des défis peuvent émerger, notamment la possibilité qu'un dataset soit supprimé dans Dataiku mais ne le soit pas dans la base de données, générant ainsi des tables fantômes déconnectées de Dataiku et donc de toute transformation. Cette situation peut entraîner des implications significatives tels que coûts de stockage supplémentaires ou encore une occupation inutile de l'espace mémoire. Si la base de données n'est pas configurée pour nettoyer automatiquement les tables non utilisées pendant un certain laps de temps, cela peut entraîner une accumulation potentiellement problématique de tables superflues.
Réponse : Afin de remédier à cette problématique, notre équipe a mis au point un plugin spécialisé. Celui-ci offre une solution en listant et comparant les datasets de Dataiku avec les tables liées à une connexion SQL. Ils ne sont pas supprimés de manière automatique, laissant la main à l'utilisateur de réaliser cette action critique. Cette approche garantit l'alignement entre les datasets et les tables de la base de données, assurant ainsi une maintenance efficace et la propreté de l'environnement de la base de données.

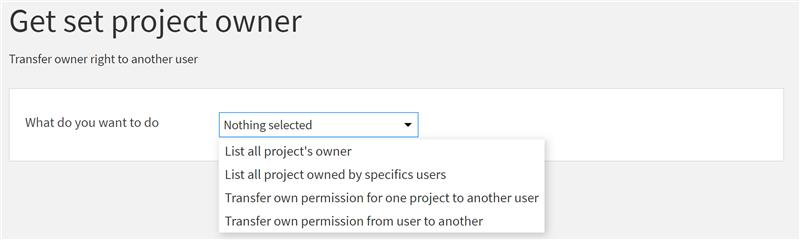
Continuité des projets après suppression de licence utilisateur
Question : Comment assurer la pérennité des projets lors de la suppression d'un compte Dataiku ?
Contexte : Dans le cadre de la maintenance d'une plateforme Dataiku cohérente et facilement gérable, la réaffectation des projets lors de la désactivation d'une licence utilisateur devient cruciale. Pour garantir la pérennité des projets, il est nécessaire de transférer les droits de propriété de chaque projet associé à l'utilisateur désactivé vers un utilisateur actif.
Réponse : À cet effet, notre équipe a développé un plugin dédié, capable de répertorier tous les utilisateurs propriétaires de projets. Il permet aussi de faciliter le transfert des droits assurant ainsi une continuité sans heurts des projets dans l'environnement Dataiku.
Gestion efficace des groupes d'utilisateurs
Question : Comment faciliter la gestion de groupes de droits pour plusieurs utilisateurs sur la plateforme Dataiku ?
Contexte : Dans le but de garantir la sécurité de l'usage de la plateforme, certains groupes de droits sont définis, impliquant les utilisateurs et les projets. La gestion manuelle des modifications de ces groupes peut rapidement devenir fastidieuse. Cela devient d'autant plus complexe lorsque de nombreux utilisateurs sont actifs sur la plateforme, et que la diversité des équipes est significative.
Réponse : Face à ce défi, nous avons élaboré une solution sous la forme d'un plugin. Il offre la possibilité d'effectuer des ajouts ou des retraits massifs de groupes pour un ou plusieurs utilisateurs simultanément, simplifiant ainsi la gestion administrative des droits et assurant une sécurité renforcée sur l'ensemble de la plateforme.

Suivi précis des connexions par dataset
Question : Comment assurer un monitoring efficace des connexions au niveau projet ?
Contexte : Pour garantir une surveillance minutieuse de l'utilisation de toutes les connexions au niveau du projet, il est essentiel de répertorier de manière exhaustive les connexions employées pour chaque dataset. Par extension, cela permet d'obtenir pour chaque projet les connexions utilisées. Lorsque beaucoup de connexions sont disponibles au sein d'une même plateforme Dataiku, il peut être difficile de s'assurer de leur bon usage au bon endroit.
Types de connexions, compréhension approfondie
Réponse : Afin de répondre à ce besoin, notre équipe a mis au point un plugin offrant la possibilité de sélectionner les types de connexions à examiner, puis de choisir les datasets à répertorier. Cette approche permet une analyse fine des connexions utilisées dans chaque projet, favorisant ainsi une compréhension approfondie de leur utilisation.
Optimisation globale des traitements
Cette démarche s'avère particulièrement intéressante pour croiser les données au sein de chaque projet, assurant ainsi leur pérennité et contribuant à l'optimisation globale des traitements et de la plateforme.

Vision complète et rapide des activités automatisées
Question : Comment effectuer rapidement un audit de l'ensemble des tâches automatisées de la plateforme à partir d'un emplacement centralisé ?
Connaissance approfondie de l'ensemble des tâches récurrentes
Contexte : Lorsqu'il s'agit de la maintenance de la plateforme, du bon fonctionnement des projets et de la stack technologique associée, il est impératif d'avoir une connaissance approfondie de l'ensemble des tâches récurrentes exécutées sur la plateforme.
Déclenchement de triggers et reporters
Dans Dataiku, ces tâches sont organisées en scénarios, déclenchées par le biais de triggers et communiquées aux équipes dédiées grâce aux reporters.
Réponse : C'est dans cette optique que nous avons mis au point un plugin qui parcourt exhaustivement l'ensemble des scénarios de la plateforme, consolidant ainsi toutes les informations pertinentes (type de trigger, type de scénario, statut d'activation, ...) dans un dataset unique. Cette approche offre une vision centralisée de l'ensemble des scénarios, facilitant ainsi le suivi, la surveillance et la prise de décisions éclairées pour garantir le bon déroulement des opérations.

Utilisation Avancée du partitionnement
Question : Comment assurer une construction efficace et maitrisée d'un dataset partitionné ?
Contexte : Le partitionnement dans Dataiku consiste à diviser les ensembles de données selon des dimensions significatives. Il en existe deux types : "discrètes", avec un petit nombre de valeurs (e. g. pays, unité commerciale), et "temporelles", divisant l'ensemble de données en périodes fixes (année, mois, jour ou heure).
La partition et l’incrémentation
La partition sert plusieurs fins, notamment l'incrémentation, assurant un recalcul à l'identique. Il y a également des avantages en termes de performances des requêtes, en particulier pour les ensembles de données basés sur des fichiers, où seuls les fichiers pertinents correspondant à la partition sont lus.
La gestion d’exécution multiples
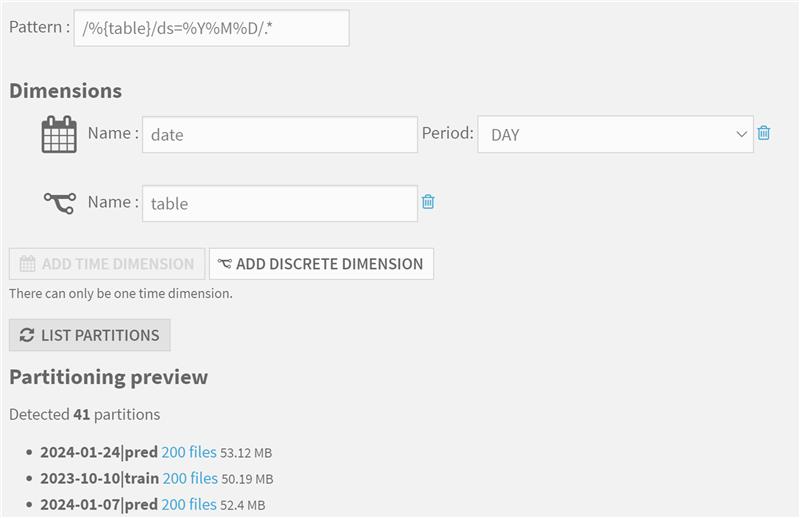
Cependant, la gestion d'exécutions multiples de partitions spécifiques ou de listes de dates discontinues peut devenir fastidieuse. Il faut alors choisir entre exécuter à la main les partitions souhaitées ou exécuter des partitions vides provoquant des warnings.
Plugin (exécution tout ou une partie de partitions)
Réponse : C'est dans cette perspective que nous avons développé un plugin permettant d'exécuter tout ou partie d'une liste de partitions, offrant ainsi la flexibilité nécessaire pour écraser les partitions si besoin. Intégrer cette fonctionnalité dans une démarche de production est particulièrement pratique car elle peut être utilisée pour des données spécifiques dans le cadre d'un run quotidien ou complet, facilitant ainsi une gestion efficace et automatisée des partitions dans un environnement opérationnel.
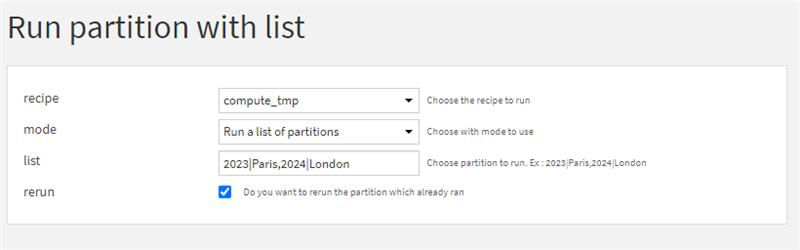
Notebooks containerisés pour une plateforme performante
Question : Comment garantir l'exécution de tous les notebooks Jupyter (Python) d'une plateforme Dataiku dans des containers ?
L’exécution de tous les notebooks Jupyter au sein de containers
Contexte : Dans le contexte du suivi de la plateforme Dataiku et de l'optimisation des performances des notebooks, il est impératif que l'intégralité des notebooks Jupyter s'exécute au sein de containers (environnement virtuel qui permet une exécution rapide et fiable des applications). Un notebook est un environnement interactif permettant d'écrire, exécuter et visualiser du code favorisant ainsi l'exploration des analyses de données. Cette approche stratégique permet aux notebooks de bénéficier pleinement des performances offertes par un container, évitant ainsi tout ralentissement potentiel de la plateforme voire un incident pouvant entraîner le crash de l'instance Dataiku. Au niveau de l'instance, il est impossible d'empêcher un notebook d'être exécuté directement en local sur l'instance Dataiku.
Plugin (Dresser la liste complète des notebooks ne s'exécutant pas dans des containers)
Réponse : Afin de répondre à cette exigence, nous avons développé un plugin permettant de dresser une liste complète des notebooks qui ne s'exécutent pas dans des containers. Ce plugin offre également des fonctionnalités avancées, notamment la possibilité de décharger ces notebooks pour libérer de la ressource, ainsi que la capacité de forcer un changement d'environement d'éxécution (e.g. local) vers un spécifique (e.g. containerisé). Ces fonctionnalités assurent un contrôle précis sur l'environnement d'exécution des notebooks, favorisant ainsi une gestion efficace des ressources et une performance optimale de la plateforme.

Vue d'ensemble des datasets sources et finaux d'un projet
Question : Comment obtenir rapidement une vue d'ensemble des datasets critiques de chaque projet ?
Identifier les tables ou les fichiers utilisés pour l'initialisation de chaque flux
Contexte : Afin d'obtenir rapidement une vue d'ensemble des datasets sources (à l'origine des flux de traitements) et des datasets cibles (en bout de chaîne), il est essentiel de surveiller l'ensemble des projets. Il convient alors d'identifier les tables ou les fichiers utilisés pour l'initialisation de chaque flux, puis de repérer les datasets qui en résultent et qui sont employés dans des applications externes, des tableaux de bord, ou d'autres contextes.
Un plugin qui permet de parcourir tous les projets
Réponse : Dans cette optique, nous avons développé un plugin qui permet de parcourir tous les projets, de répertorier les datasets à l'origine et à la conclusion de chaque flux de données, et de fournir des informations détaillées concernant leur type et la connexion utilisée.
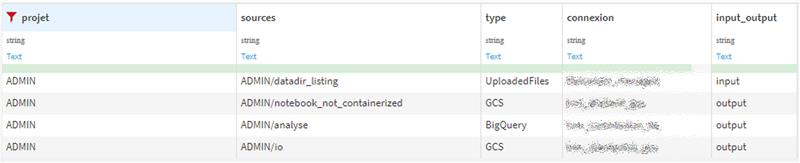
Validation des prérequis avant le déploiement en production
Question : Comment garantir que les prérequis d'un projet soient satisfaits avant de le déployer en production ?
Vérifier le bon fonctionnement du projet, disposer d'une documentation exhaustive, maintenir la qualité des données et d'automatiser les processus
Contexte : Afin de garantir la réussite du déploiement d'un projet en production, il est impératif de vérifier le bon fonctionnement du projet, de disposer d'une documentation exhaustive, de maintenir la qualité des données et d'automatiser les processus. Cette exigence nécessite la validation d'une liste complète de points, comprenant par exemple la description du projet, des zones et des scénarios. Elle requiert également une évaluation des scénarios, de leur temps de traitement et de leur déclenchement, ainsi que des vérifications sur les checks et les metrics du projet. Enfin, une attention est portée sur les bundles (snapshot du projet à instant précis) créés et les modèles de Machine Learning entraînés et utilisés, avec une considération particulière pour leur taille sur l'instance.
Une macro permettant à tous les utilisateurs de Dataiku d'obtenir une vue d'ensemble d'un projet
Réponse : Dans cette optique, nous avons développé une macro (automatisation d'actions prédéfinis) qui offre la possibilité à tous les utilisateurs de Dataiku d'obtenir une vue d'ensemble d'un projet. Cette vue, la plus complète possible, reprend la liste non exhaustive mentionnée ci-dessus, facilitant ainsi la validation complète des prérequis avant le déploiement en production. Les utilisateurs peuvent donc exécuter cette macro au cours du développement d'un projet, pour s'assurer que la documentation est bien réalisée, que les modèles de Machine Learning ne soient pas trop volumineux, etc.
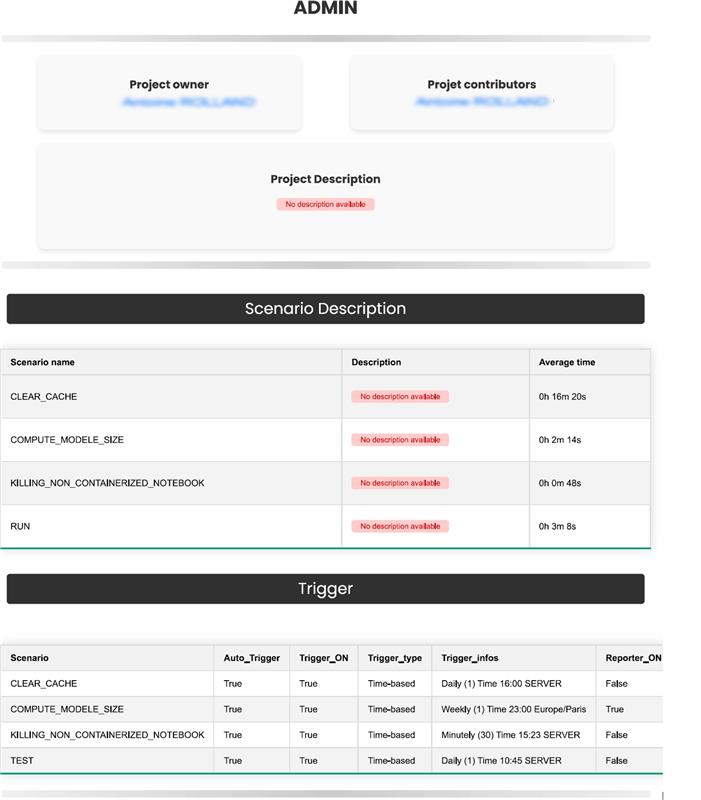
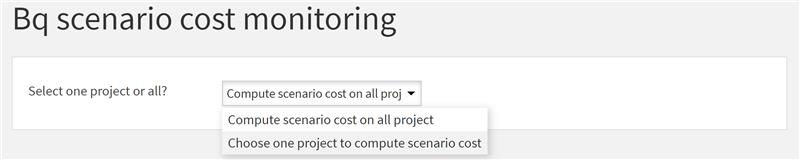
H2 : Maîtrisez les coûts d'exécution de vos tâches automatisées dans le cloud
Question : Comment connaître et contrôler le coût d'exécution dans le cloud des tâches automatisées ?
H3 : La quantité de données traitées, le temps de traitement et les ressources utilisée
Les coûts d'une requête SQL dans le cloud sont principalement déterminés par la quantité de données traitées, le temps de traitement et les ressources utilisées, tels que la puissance de calcul et la mémoire et le stockage. Les coûts sont indiqués en volume de données qu'il faudra ensuite convertir en tarif.
H3 : Connaître de manière précise le coût de chacune des tâches
Contexte : Afin de pouvoir monitorer les coûts des tâches automatisées et de les optimiser, il faut connaître de manière précise le coût de chacune des tâches. Malheureusement, cela n'est pas disponible nativement dans Dataiku. Bien qu'il soit envisageable d'obtenir manuellement le coût de chaque tâche, cette approche se révèlerait trop chronophage et peu pratique si elle devait être appliquée à l'ensemble des tâches. Il est donc nécessaire de trouver une solution plus efficace et automatisée pour répondre à ce besoin.
H3 : Un plugin pour parcourir toutes les étapes exécutées
Réponse : Dans le but de répondre à ce besoin, nous avons développé un plugin qui permet de parcourir toutes les étapes exécutées par un scénario donné. Ce plugin est conçu pour obtenir le coût individuel de chaque étape et pour agréger ces résultats dans un tableau synthétique. Grâce à cet outil, il est désormais possible de connaître le coût global de chaque scénario, facilitant ainsi le suivi et l'optimisation des coûts associés aux tâches automatisées dans Dataiku.

Maîtriser les tâches automatisées avant leur déploiement
Question : Comment s'assurer qu'un scénario est prêt à être déployé en production ?
Dataiku : Vérifier la dernière exécution du scénario
Contexte : Dans Dataiku, les scénarios représentent un ensemble de tâches automatisées. Ils peuvent contenir des suites de transformations de tâches, d'éxécution de code python ou encore de scripts SQL. Cependant, entre le moment où un scénario a été validé et le déploiement, il se peut que certaines tâches ou le scénario lui-même aient évolué. Il convient donc de vérifier si la dernière exécution du scénario correspond à la dernière version de celui-ci.
Dataiku : une macro analysant l’intégralité des scénarios d’un projet
Réponse : Pour aborder cette problématique qui n'est pas intrinsèquement prise en charge par Dataiku, nous avons élaboré une macro qui examine l'intégralité des scénarios d'un projet, ainsi que toutes les tâches qui en font partie. Cette macro vérifie plusieurs points cruciaux :
ol  {margin-bottom:0in;margin-top:0in;}ul {margin-bottom:0in;margin-top:0in;}li {margin-top:.0in;margin-bottom:8pt;}ol.scriptor-listCounterResetlist!list-f07f2e92-4039-4c0b-85f0-051cd67b4d501 {counter-reset: section;}ol.scriptor-listCounterlist!list-f07f2e92-4039-4c0b-85f0-051cd67b4d501 {list-style-type:bullet;}li.listItemlist!list-f07f2e92-4039-4c0b-85f0-051cd67b4d501::before {counter-increment: section;content: none; display: inline-block;}
- Nous nous assurons que la dernière exécution de chaque scénario s'est soldée par un succès.
- Nous contrôlons que les étapes de chaque scénario n'ont subi aucune modification depuis le dernier succès d'exécution.
- Nous confirmons que les recettes n'ont pas été modifiées depuis la dernière exécution du scénario.
- Nous vérifions que toutes les tables faisant l'objet d'appels dans les requêtes SQL existent bien en tant qu'entrées.
- Enfin, nous nous assurons que le contenu des étapes Python ou SQL n'a pas été modifié.
Dataiku : des résultats clairs dans un tableau de bord statique
Enfin, pour une visualisation claire et facile des résultats de ces vérifications, nous avons choisi de les restituer sous forme de tableau de bord statique dans Dataiku. Ce tableau de bord offre une vue d'ensemble des résultats des vérifications effectuées sur chaque scénario et ses tâches associées, permettant ainsi une compréhension rapide et efficace de l'état de santé du projet. Les utilisateurs peuvent ainsi facilement identifier les éventuels problèmes et prendre les mesures nécessaires pour y remédier.

Quitter Hadoop pour le Cloud
Question : Comment passer d'une plateforme avec un cluster Hadoop à une plateforme cloud ?
Limites des plateformes Hadoop pour la gestion des données
Contexte : De nombreuses entreprises utilisent encore des plateformes Hadoop pour gérer leurs données. Cependant, cette technologie présente des limites importantes telles qu'une faible élasticité, la difficulté à gérer les pics de charge ou l'inadaptabilité à l'analyse SQL. On peut y rajouter des coûts d'administration et de maintenance élevés, ainsi qu'une dépendance aux équipes IT. Ces limites rendent les environnements statiques et peu souples. Lorsque l'on intègre Hadoop avec une plateforme Dataiku, on se retrouve avec de faible performance et des traitements DSS bridés.
Une alternative moderne pour vos données : Le cloud
Pour remédier à ces problèmes, le cloud s'impose comme une alternative moderne, simple et flexible. L'objectif principal de la migration vers le cloud est de réaliser une transition sans douleur, tout en minimisant le temps de double-run et les régressions. Il est également essentiel de ne pas perdre de fonctionnalités pour offrir une expérience transparente aux utilisateurs.
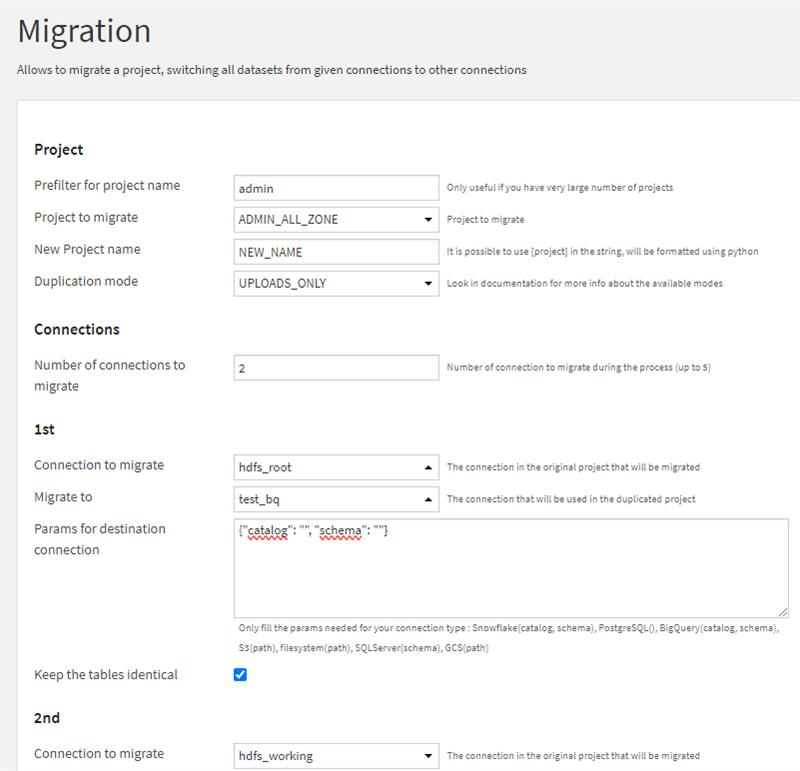
Réponse : Nous avons mis au point une méthode développée sous forme de plugin pour faciliter la migration d'une plateforme Dataiku Hadoop vers le cloud, tout en optimisant les performances et en réduisant le temps de déploiement. Notre approche se concentre sur trois aspects clés pour garantir une migration réussie.
Mapping Dataiku : un gain de temps + migration cloud
Tout d'abord, nous nous efforçons de maximiser le gain de temps en exploitant au mieux les capacités de mapping de Dataiku et en automatisant les tâches répétitives via l'API. Cette approche permet de réduire considérablement le temps nécessaire à la migration.
Ensuite, nous nous assurons que la migration vers le cloud se traduise par des performances optimales. Notre méthode garantit une parfaite adhérence au nouvel environnement cloud, en tirant parti de l'élasticité du socle technique, qui permet d'optimiser les performances.
Enfin, nous veillons à ce que la migration se fasse sans régression. Nous nous assurons que les flux et les recettes SQL et python restent identiques, tout en optimisant les scripts lorsque cela est possible. Cette approche garantit une migration sans régression, offrant une expérience utilisateur transparente.
Identification des datasets alimentés en mode delta
Question : Comment obtenir une liste exhaustive des jeux de données alimentés à l'aide du mode delta ?
Le mode delta est une méthode d'ingestion de données incrémentielle
Elle consiste à ne charger que les nouvelles données ou les modifications apportées aux données existantes, plutôt que de charger l'ensemble du jeu de données à chaque fois.
Contexte : L'optimisation des flux de données est une préoccupation majeure dans la gestion des données. L'utilisation du mode delta offre un avantage significatif en permettant d'ajouter uniquement les données qui n'ont pas encore été transformées, ce qui permet d'économiser des ressources de calcul précieuses. Dans cette optique, il est crucial de connaître tous les jeux de données qui sont alimentés de cette manière. En cas d'incident, une gestion adéquate de ces jeux de données est essentielle pour garantir la continuité des opérations et minimiser les temps d'arrêt.
Plugin conçu pour répertorier tous les jeux de données alimentés en mode delta
Réponse : Pour répondre à cette problématique, nous avons développé une solution sous la forme d'un plugin conçu pour répertorier tous les jeux de données alimentés en mode delta. Ce plugin offre ainsi une vue d'ensemble pour une surveillance proactive et une réaction rapide en cas de besoin. Grâce à cet outil, les équipes chargées de la gestion des données peuvent facilement identifier les jeux de données concernés et prendre les mesures nécessaires pour garantir une gestion efficace en cas d'incident.
Optimisation de la plateforme Dataiku : gestion des datasets en cache
Question : Comment garantir la performance optimale de la plateforme Dataiku en mettant l'accent sur la gestion des datasets en cache ?
Réduire les temps de chargement lors de l'exploration de la donnée
Contexte : Afin de réduire les temps de chargement lors de l'exploration de la donnée ou de sa représentation graphique dans un dataset, les données sont mises en cache. Cependant, plus le nombre de datasets est conséquent, plus l'espace occupé par ces données en cache l'est aussi. Pour garantir la performance optimale de la plateforme Dataiku, une attention particulière est à accorder à cette gestion des datasets en cache. Il devient alors essentiel, surtout lorsque de nombreux projets et, par conséquent, de nombreux datasets sont créés sur l'instance, de procéder au nettoyage des datasets en cache régulièrement. Malheureusement, aucune option n'est actuellement disponible pour effectuer cette opération à l'échelle de l'ensemble de l'instance.
Un plugin capable de vider le cache de chacun des datasets
Réponse : C'est dans cette perspective que nous avons développé un plugin capable de parcourir tous les projets de l'instance et de vider le cache de chacun des datasets. Ainsi, la plateforme bénéficie d'une meilleure performance, et un nettoyage régulier est appliqué pour maintenir une efficacité optimale.



