
Applying ML Ops to Data Science
For the past few years, I have been very interested in ML Ops and in particular in the facilities that DSS (Dataiku Data Science Studio) offers in this area.
Full disclaimer: ML Ops and in that DevOps and CI/CD (Continuous Integration & Continuous Deployment) is a sprawling subject... And it's clearly not in one article that I'm going to go around! If you want a detailed overview, I invite you to read the white paper produced by Dataiku on the subject: O'Reilly Introducing MLOps.
One of the aspects of ML Ops that I wanted to talk about today is the implementation of CI/CD processes on Data Science projects... OK, ready for a very dense and technical article? Let's go!
Why integrate DevOps or the world of Data Science?
The big difference between the Data Science we do today, and the one we did a few years ago... The fact is that the projects are now going into production. Gone are the days of the Python Notebook locally on the developer's computer! For example, at Eulidia our Data Science infrastructure (based on DSS) is this:

The evolution of Data Science towards production
So we have: a DEV environment for the design of the project, a recipe environment for technical and functional tests, a PROD environment for the run... But also delivery pipelines, repos for project versioning, governance, data catalog, etc. etc.
What organization am I putting in front of these tools, who is responsible for what?
Inevitably, this raises questions:
- What organization am I putting in front of these tools, who is responsible for what?
The challenges raised: Stability of automated project deliveries
- If I automate the delivery of projects, how can I ensure their stability?
The challenges raised: Monitoring of models in production.
- Once my models are in production, how can I monitor their drift?
... and so on. To answer all this, it is a mixture of organization, project processes and tools. And in the middle of all this, we find the interest of CI/CD methods.
Purpose of the CI/CD
CI/CD in Data Science: what are we talking about?
OK but what does doing CI/CD on Data Science mean in concrete terms?
Let's start from the basics: the objective of a CI/CD process is above all to accelerate and streamline the production of projects. It is a question of moving away from a vision where the project would be delivered in a monolithic manner at the end of a long development process, to instead favor very regular deliveries based on a logic of continuous improvement.
In order to enable this type of approach, developers need to have as much autonomy as possible. They are therefore offered automatic deployment pipelines, making it possible to limit compartmentalization with third party teams such as IT/Ops.
The CI/CD process
A standard CI/CD process is generally based on the following workflow:
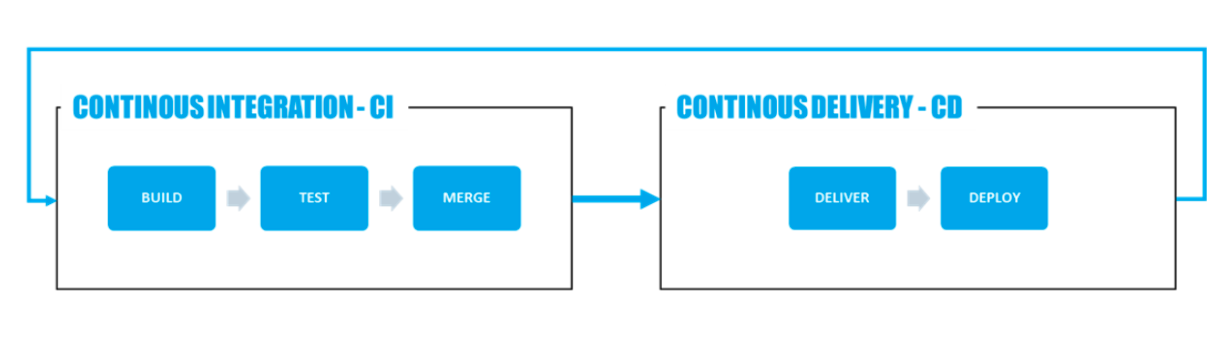
So there are two main aspects to cover:
Continuous integration (CI)
Continuous integration implies that the functionalities under development on a given project are integrated as and when they are finalized into a “stable version” that can be deployed in production. This involves several needs:
- Collaborative build capabilities — several developers are working on the project in parallel.
- Automated unit tests — changes made should be tested over time to ensure overall operation.
- Notion of stable version — a stable version of the project must always be available for deployment in production.
Continuous delivery (CD)
Continuous delivery means that stable versions of the project will be automatically tested and deployed to production, minimizing manual actions (including rewriting effort) as much as possible. This process is based on 2 constraints:
- Automatic deliveries — stable versions are automatically collected from a repository (usually Git), prepared for deployment and then sent to production environments.
- Automatic deployment — each stable version received is automatically deployed as an upgrade to the existing project. This generally involves automatic testing (integration, not regression).
On our Data Science projects, these steps are relatively natural!
Depending on your tools, the CI/CD prerequisites will be more or less well covered. With DSS, we implemented the following elements:

- Build: each stage is individually versioned.
- Unit tests: we use the concept of Metrics & Checks, which allows us to validate unit tests each time our key datasets are rebuilt.
- Stable version: the concept of Bundle allows you to take a photo of the project at each stable release, and to number and log these versions.
- Automatic deliveries: the Deployer Node serves as a repo for published stable versions. Delivery pipelines automatically launch our daily deliveries.
... What about automatic deployment, and associated tests?
For automatic deployment, we stayed on the classic: a Jenkins pipeline that interfaces to the DSS servers via the dedicated API and which:
- Get the bundles,
- Deploy them in recipes, runs integration tests,
- Run non-regression tests and then deploy the validated version to production.
The only problem: DSS does not allow the execution of non-regression tests!
So how can we ensure that the latest developments in the project have not called into question the expected behavior?
No non-reg tests on DSS? OK, we're developing the missing feature
With DSS allowing to extend the functionalities of the platform through plugin development, we built a component that adds the necessary functionalities. To do this, we set up a working group with Dataiku directly, as well as a team at one of our customers.
After a lot of back and forth, we decided to use scenario logic, which allows us to organize and plan the execution of projects, and we added 2 custom steps that can be instantiated on each of our projects.
To conduct our non-regression tests, the objective is to execute the project on test data (for which we know the expected output), then to measure the difference between the real and the expected outputs.
1 - Build stage
This step takes your project and test games into parameters. It “unplugs” the current inputs/outputs from your workflow, plugs in the test sets instead, executes the project, then returns it to its original state:

Once executed, the project is output in its original state (so it is non-invasive), plus a dataset containing the outputs produced from the test data.
2 - Test step
We must now compare this dataset that we have just produced with the outputs that we expected to have. Here we choose the type of tests we want to conduct (line-by-line comparison, column format, etc.) and the location where we want to write our test report.

At the output, we can therefore analyze the differences between the project outputs and those we expected to have! If everything is ok, we continue with the deployment process in production. If there are differences, we call on the human expert who judges whether or not the project should be revised.
And now what is going on?
For our part, we finally packaged all this, in the form of a plugin that we distribute. We also took the opportunity to establish this ML Ops method for DSS, which we deploy with our customers!
If you want to know more, you can find this talk I gave on the subject: ML Ops: From Buzzword to Reality
Are you, your Data Science projects already in production?



