
Appliquer le ML Ops à la Data Science
Depuis quelques années, je m'intéresse beaucoup au ML Ops et en particulier aux facilités que DSS (Dataiku Data Science Studio) offre en la matière.
Full disclaimer : le ML Ops et dedans le DevOps et le CI/CD (Continuous Integration & Continuous Deployment) est un sujet tentaculaire... Et ce n'est clairement pas en un article que je vais en faire le tour ! Si vous en voulez une vision détaillée, je vous invite à lire le livre blanc qu'a produit Dataiku sur le sujet : O'Reilly Introducing MLOps.
Un des aspects du ML Ops dont je voulais parler aujourd'hui, c'est la mise en œuvre de processus CI/CD sur des projets de Data Science... OK, prêts pour un article bien dense et technique ? C'est parti !
Pourquoi intégrer le DevOps ou monde de la Data Science ?
La grosse différence entre la Data Science que l'on fait aujourd'hui, et celle que l'on faisait il y a encore quelques années... C'est que les projets partent maintenant en production. Terminée l'époque du Notebook Python en local sur le poste du développeur ! A titre d'exemple, chez Eulidia notre infra Data Science (à base de DSS) c'est ça :

L'évolution de la Data Science vers la production
On a donc : un environnement de DEV pour la conception du projet, un environnement de recette pour les tests techniques et fonctionnels, un environnement de PROD pour le run... Mais aussi des pipelines de livraison, des repo pour le versioning projet, de la gouvernance, du data catalogue, etc. etc.
Quelle organisation je mets en face des ces outils, qui est responsable de quoi ?
Forcément, ça soulève des questions :
- Quelle organisation je mets en face des ces outils, qui est responsable de quoi ?
Les enjeux soulevés : Stabilité des livraisons de projet automatisées
- Si j'automatise la livraison des projets, comment s'assurer de leur stabilité ?
Les enjeux soulevés : Monitoring des modèles en production.
- Une fois mes modèles en production, comment monitorer leur dérive ?
... et ainsi de suite. Pour répondre à tout ça, c'est un mélange d'organisation, de processus projet et d'outillage. Et au milieu de tout ça, on retrouve l'intérêt des méthodes de CI/CD.
Objectif du CI/CD
CI/CD en Data Science : de quoi parle-t-on ?
OK mais concrètement, faire du CI/CD sur de la Data Science, ça veut dire quoi ?
Partons des bases : l'objectif d’un processus CI/CD, c'est avant tout d’accélérer et fluidifier la mise en production des projets. Il s’agit de sortir d’une vision où le projet serait livré de façon monolithique à l’issue d’un long processus de développement, pour plutôt privilégier des livraisons très régulières sur une logique d’amélioration continue.
Afin de permettre ce type d’approche, les développeurs doivent bénéficier d’autant d’autonomie que possible. On leur propose donc des pipelines de déploiement automatique, permettant de limiter le cloisonnement vis-à-vis des équipes tierces de type IT/Ops.
Le processus de CI/CD
Un processus CI/CD standard repose généralement sur le Workflow suivant :
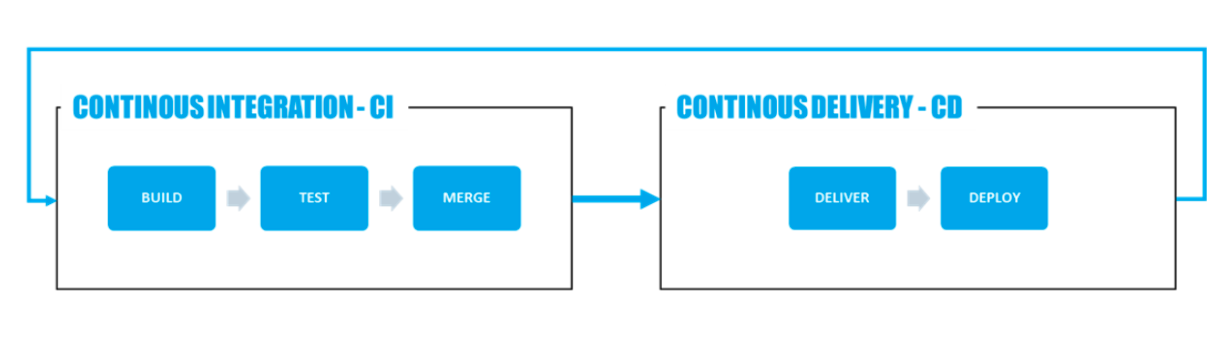
Il y a donc deux aspects principaux à couvrir :
Intégration continue (CI)
L’intégration continue implique que les fonctionnalités en cours de développement sur un projet donné soient intégrées au fur et à mesure de leur finalisation à une « version stable », déployable en production. Cela implique plusieurs besoins :
- Capacités de build collaboratif – plusieurs développeurs travaillent en parallèle sur le projet.
- Tests unitaires automatisés – les modifications apportées doivent être testées au fil de l'eau pour garantir le bon fonctionnement global.
- Notion de version stable – une version stable du projet doit constamment être disponible pour le déploiement en production.
Livraison continue (CD)
La livraison continue signifie que les versions stables du projet seront automatiquement testées et déployées en production, en minimisant autant que possible les actions manuelles (notamment l’effort de réécriture). Ce processus repose sur 2 contraintes :
- Livraisons automatiques – les versions stables sont collectées automatiquement depuis un repository (généralement Git), préparées pour le déploiement puis envoyée vers les environnements de production.
- Déploiement automatique – chaque version stable reçue est automatiquement déployée sous forme de montée de version du projet existant. Cela implique généralement des tests automatiques (intégration, non régression).
Sur nos projets de Data Science, ces étapes sont relativement naturelles !
Selon vos outils, les prérequis du CI/CD seront plus ou moins bien couverts. Avec DSS, on a mis en place les éléments suivants :

- Build : chaque étape est individuellement versionnée.
- Tests unitaires : on utilise le concept de Metrics & Checks, qui permet de valider des tests unitaires à chaque reconstruction de nos datasets clés.
- Version stable : le concept de Bundle permet de prendre une photo du projet à chaque version stable, de numéroter et d'historiser ces versions.
- Livraisons automatiques : le Deployer Node sert de repo pour les versions stables publiées. Des pipelines de delivery lancent automatiquement nos livraisons quotidiennes.
... Quid du déploiement automatique, et des tests associés ?
Pour le déploiement automatique, on est resté sur du classique : un pipeline Jenkins qui s'interface aux serveurs DSS via l'API dédiée et qui:
- Récupère les bundles,
- Les déploie en recette, exécute les tests d'intégration,
- Exécute des tests de non régression, puis déploie la version validée en production.
Seul problème : DSS ne permet pas l'exécution de tests de non régression !
Comment, donc, s'assurer que les dernières évolutions du projet n'ont pas remis en question le comportement attendu ?
Pas de tests de non-reg sur DSS ? OK, on développe la fonctionnalité manquante
DSS permettant d'étendre les fonctionnalités de la plateforme via le développement de plugin, on à construit un composant qui ajoute les fonctionnalités nécessaires. On a monté pour ça un groupe de travail avec Dataiku directement, ainsi qu'une équipe chez l'un de nos clients.
Après pas mal d'aller-retours, on a décidé d'utiliser la logique de scénario, qui permet d'organiser et planifier l'exécution des projets, et on a ajouté 2 étapes custom qui peuvent être instanciées sur chacun de nos projets.
L'objectif est, pour mener nos tests de non régression, d'exécuter le projet sur des données de test (dont on connait l'output attendu), puis de mesurer l'écart entre les output réels et ceux prévus.
1 - Etape de Build
Cette étape prend en paramètre votre projet et les jeux de test. Elle "débranche" les input/output actuels de votre workflow, branche à la place les jeux de test, exécute le projet, puis le remet dans son état d'origine :

Une fois exécutée, on récupère en sortie le projet dans son état d'origine (donc c'est non invasif), plus un dataset contenant les outputs produits à partir des données de test.
2 - Etape de test
Il faut maintenant comparer ce dataset que l'on vient de produire avec les outputs que l'on s'attendait à avoir. On choisi ici le type de tests que l'on veut mener (comparaison ligne à ligne, format des colonnes, etc.) et l'emplacement où l'on veut écrire notre rapport de test.

En sortie, on peut donc analyser les différences entre les output de projet et ceux que l'on s'attendait à avoir ! Si tout est ok, on poursuit le processus de déploiement en production. Si il y a des différences, on fait appel à l'expert humain qui juge si il faut réviser le projet, ou pas.
Et maintenant, il se passe quoi ?
De notre côté, on a finalement packagé tout ça, sous forme d'un plugin que l'on distribue. On en a aussi profité pour établir cette méthode ML Ops pour DSS, que l'on déploie chez nos clients !
Si vous voulez en savoir plus, vous pouvez retrouver ce talk que j'avais donné sur le sujet : ML Ops: from buzzword to reality
Et-vous, vos projets Data Science tournent-ils déjà en production ?



