
For several years, Eulidia has been supporting its customers on Dataiku, and has seen numerous updates. But some of them really shake things up. With version 13, Dataiku introduced new features that concretely improve the lives of project teams. Here is our selection (excluding GenAI) of the 4 advances not to be missed.
Git merges in the interface: a real step towards smooth collaboration
Dataiku has always made it easy for multidisciplinary teams to collaborate on data projects. But when several people are working simultaneously on a DSS project, it can quickly be chaos:
- We are losing track of changes, and it is becoming complex to identify precisely who made what changes, when and for what reason
- You can break (unintentionally) a pipeline due to poor handling
- You're crushing the work of your colleagues. If several contributors edit the same elements at the same time, this creates conflicts or overwrites the work of others.
A version control system in Dataiku
To address this problem, Dataiku integrates a version control system based on Git. It makes it possible to trace the changes made (code, recipes, scenarios...) in order to facilitate collaboration and to maintain a clear history of the project.
H3: work on a stable and functional version of the project
In its main use, the control version allows you to work on a stable and functional version of the project, while benefiting from development branches separate from the main branch, used to develop new functionalities in a safe environment.
Until now, it was possible to create new branches, but not to merge them. But with V13, we can finally manage the Merge directly in the interface, visualize conflicts, resolve them visually, and maintain control.
Concrete case: a scoring model to streamline the data project
Concrete case: A scoring model is already in production but new business data is now available. The Data team can therefore experiment with a new scoring model with the ambition of improving business metrics. During this experimentation phase, it is therefore useful to work on a secure version that is uncorrelated from the production version in order not to impact it (because we are not certain that the new version is better than the old one). Once the model is validated, it can then be merged into the main branch directly from the Dataiku interface.
Concretely, this makes it possible to meet the main challenges of collaborative work:
- Monitoring changes: Each modification is recorded: we know who changed what, when, and why. During each merge, a comment can be added to document the choices made, which improves the collective understanding of the project.
- Restoration in case of error: An error in a recipe? A script deleted by mistake? It is possible to go back to a previous stable version, whether it is an object, a file, or the entire project.
- Conflicts between developers: Thanks to version control, everyone can work on a separate branch, limiting the risk of conflicts. And if there is a conflict, the resolution integrated into the interface makes it possible to resolve it without leaving Dataiku.
Dataiku V13: What's changing
So what changes with V13:
- H3: The management of Merge from the graphical interface
- H3: Comparing two branches and identifying differences
- H3: Resolving conflicts visually
- H3: Managing the branch merge properly, and without having to go through Git
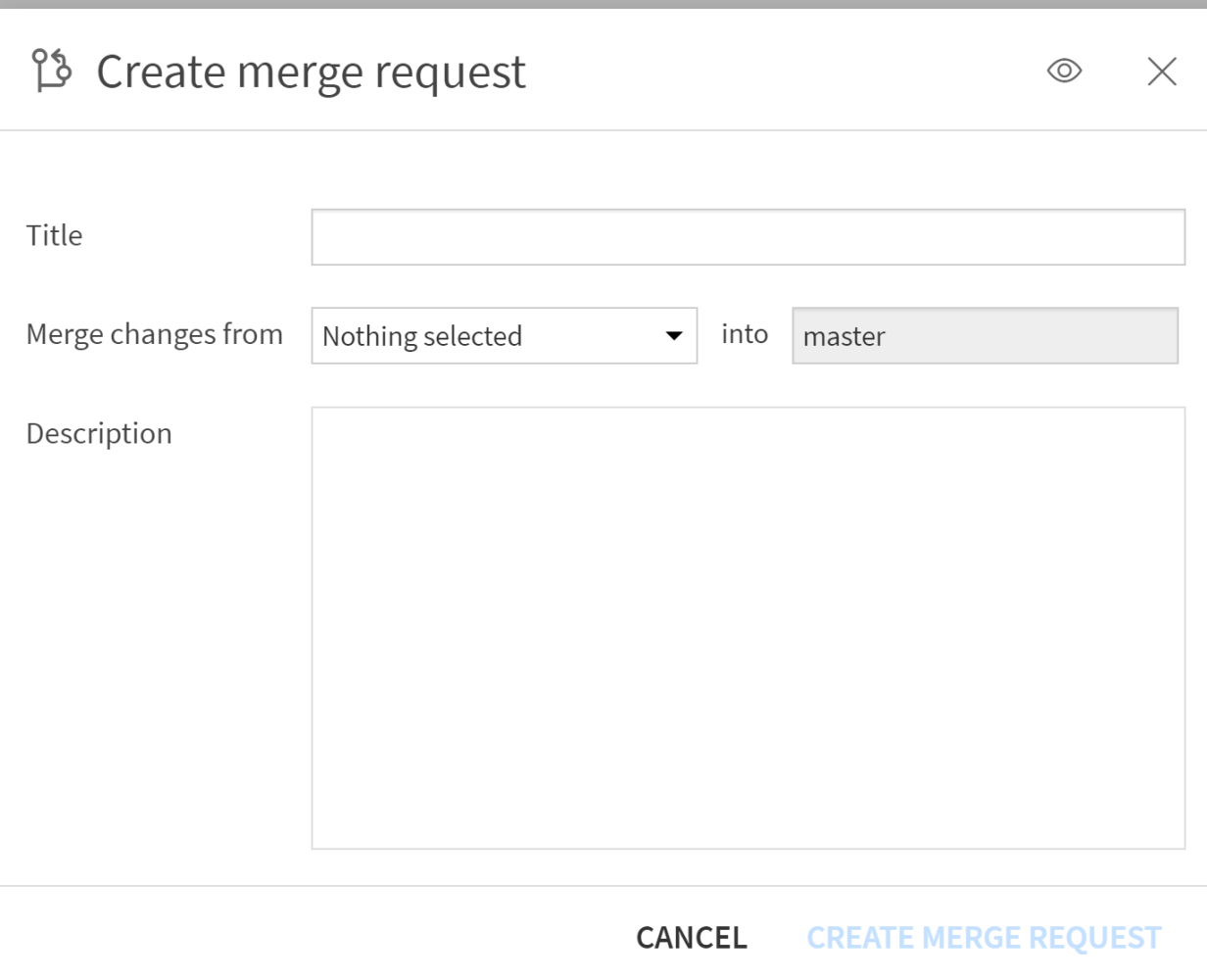

With this innovation, Dataiku continues to strengthen its position as a collaborative platform that is accessible to all data profiles. A welcome advance for teams that industrialize their analytical workflows on a large scale.
Link: https://doc.dataiku.com/dss/latest/release_notes/13.html#new-feature-builtin-git-merging
Data Quality: an essential prerequisite for any data project
We have long known that data quality is the basis for the success of any data project. Without reliable, comprehensive, and consistent data, even the most sophisticated models become ineffective. Wrong data, and all your analysis goes off the rails. Data quality is not a luxury, it is a foundation.
Centralized and visual management of quality policies via Dataiku V12.6
In its V12.6, Dataiku introduces centralized and visual management of quality policies to ensure more reliable and auditable pipelines.
In practice, several situations can cause problems:
- the initial data quality is unsatisfactory
- the data may change (adding data to a dataset etc.) and the quality may become unsatisfactory as a result of the changes.
Example of unsatisfactory quality data to avoid
Data of unsatisfactory quality can take different forms depending on the case.
For example:
- Missing values on critical fields, such as a customer ID or a product code.
- Inconsistent or outlier values, such as birth dates in the future.
- An abnormally high nullity rate as a result of a poorly defined join between two data sets.
Dataiku: A mechanism for monitoring data quality
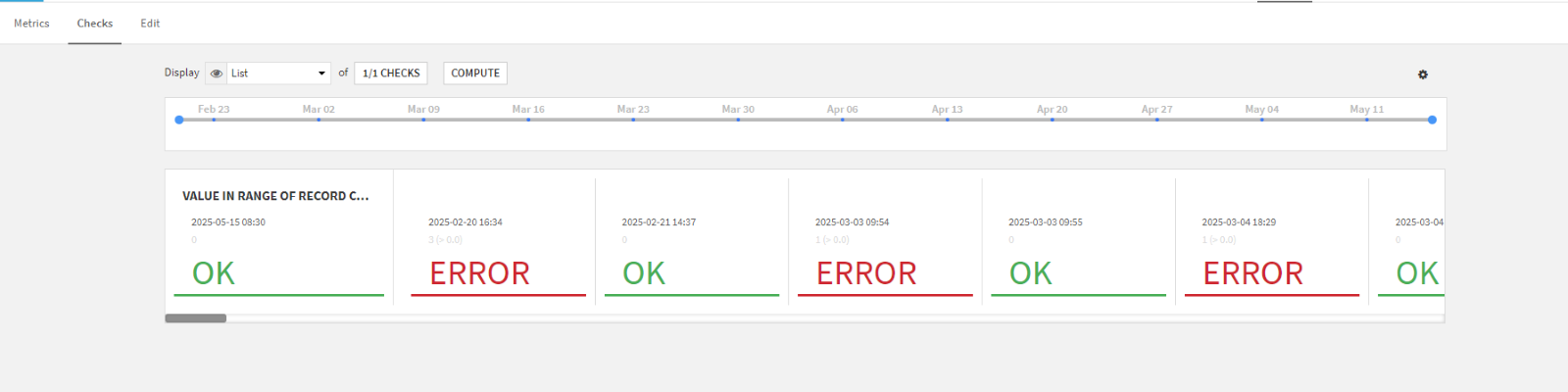
It is to respond to this problem that Dataiku has implemented a data quality monitoring system. This mechanism makes it easy to verify that the data meets personalized quality standards, and to automatically monitor its status. A data quality rule tests whether a dataset meets certain defined conditions.
The resulting status can take one of the following values:
✅ OK: the condition is met
⚠️ Warning: attention, a threshold has been reached
❌ Error: the rule is broken
⭕ Empty: the condition could not be evaluated
Prior to this release, data quality monitoring was limited to metrics and checks defined individually at the level of each dataset. With V12.6, Dataiku introduces a “Data Quality” module directly integrated into the datasets interface.
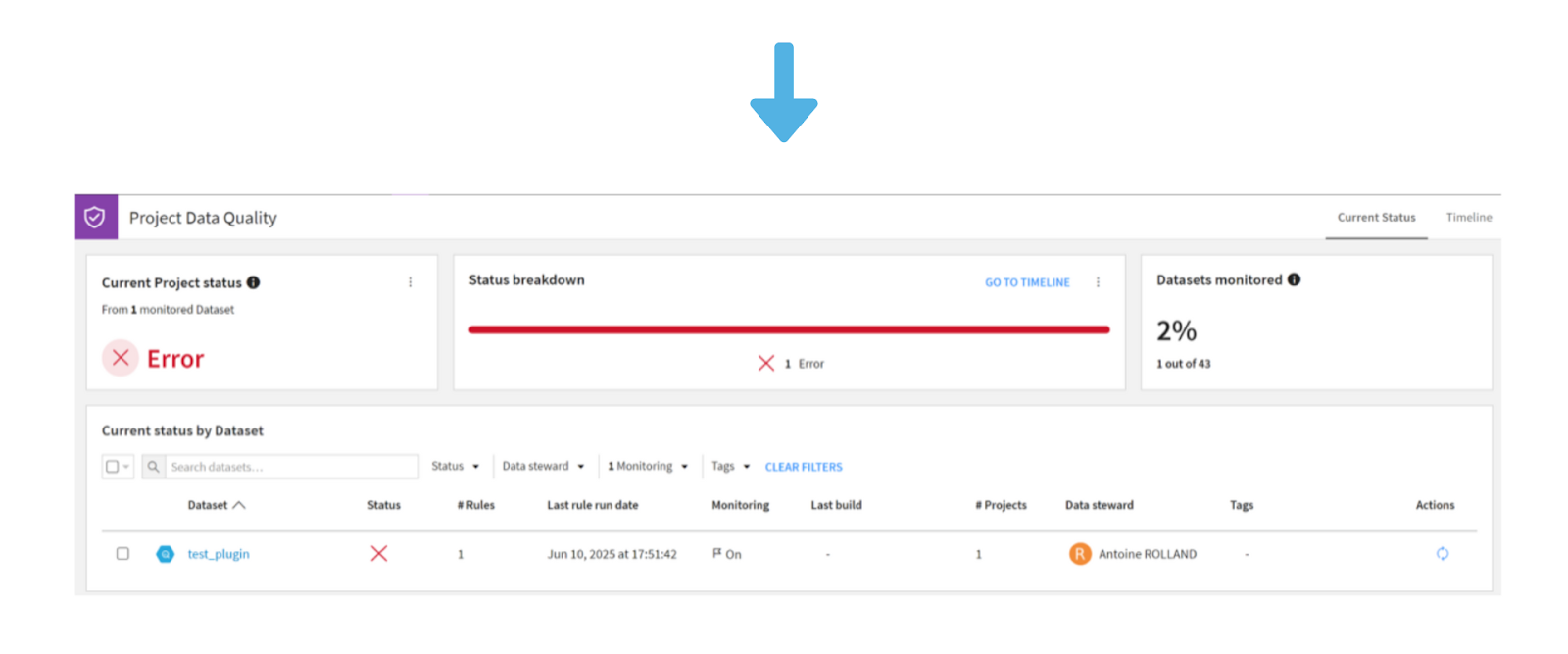
Another major evolution: the arrival of Data Quality Templates. These models include sets of preconfigured quality rules that can be easily applied to multiple datasets. They are global to the DSS instance, allowing all users to share, reuse, and standardize quality controls across a project.
Changes that simplify large-scale work on data projects.
Link: https://doc.dataiku.com/dss/latest/release_notes/12.html#data-quality
Data Lineage: for better traceability of data in your projects
In a context where data pipelines are becoming more and more complex, data traceability is no longer a luxury, but a necessity. Understanding where data comes from, how it has been transformed, and which data products are impacted by a modification has become essential to ensure the reliability and transparency of treatments.
The Risks of Unclear Traceability
Without clear traceability, several risks appear:
- H4: Lack of data transparency
- H4: Propagation of errors
- H4: Misunderstanding the impact of changes
It is to respond to these problems that Dataiku has implemented a Data Lineage system. It allows you to follow the evolution of the data through a flow to understand the evolvations/modifications undergone.
This makes it possible to provide answers to the previous problems:
- More transparency on the data because it allows you to visualize the complete path of the data
- Less error propagation because Data Lineage makes it possible to quickly identify all entities impacted by a modification or error
- Less misunderstanding of the impact of changes for the same reasons
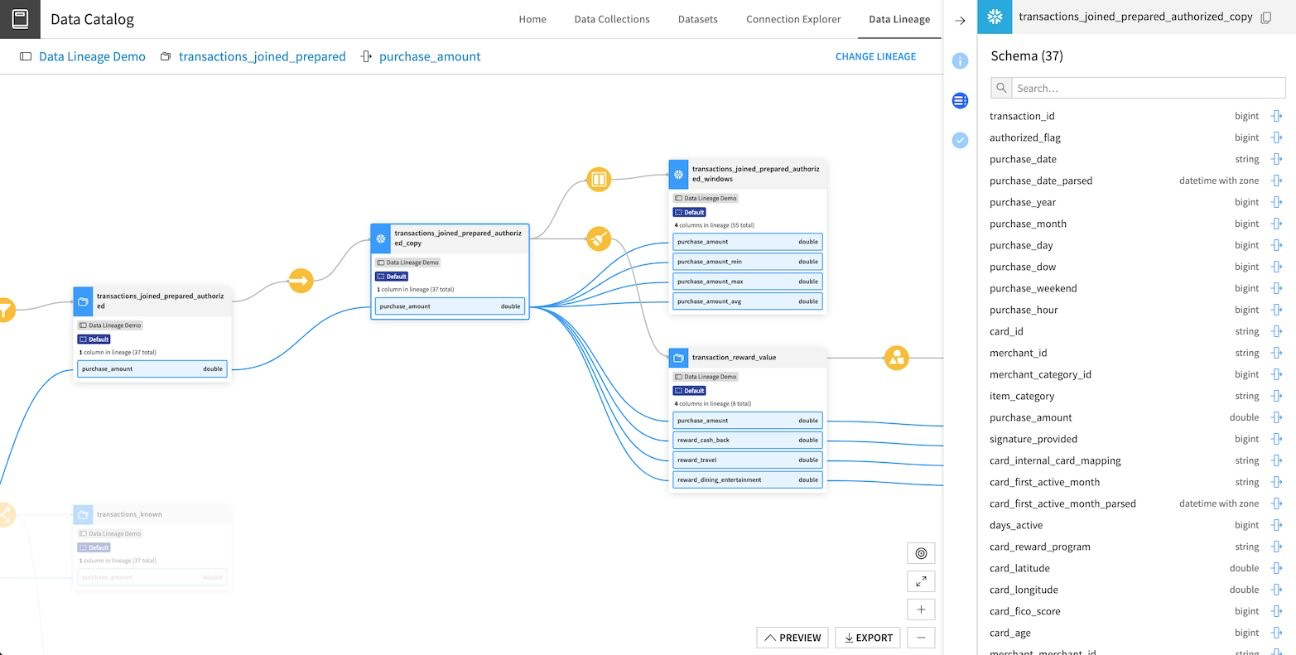
Be careful though, for Python or SQL recipes, the lineage is not generated automatically. It will therefore be necessary to define it manually so that it can be correctly propagated in the rest of the flow.
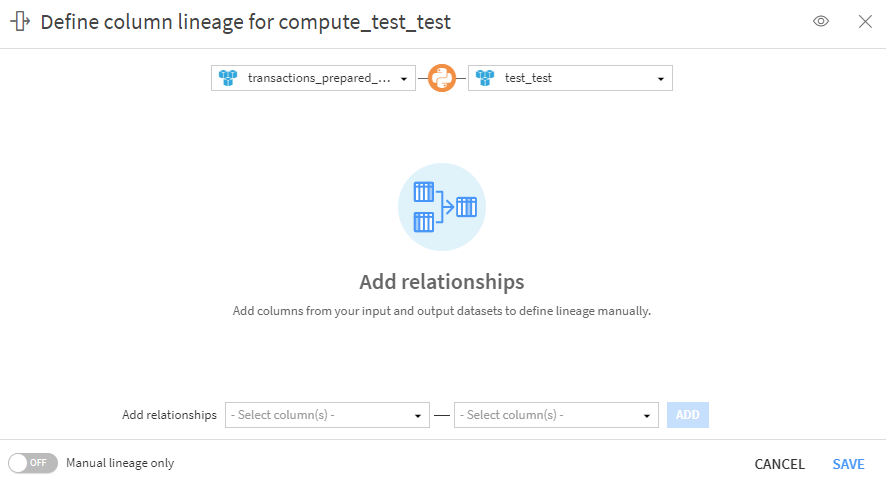
Link: https://doc.dataiku.com/dss/latest/release_notes/13.html#new-feature-column-level-data-lineage
AI-assisted recipe creation
A gain of time and more autonomy for teams
In an environment where speed of execution and ease of implementation are key challenges, advances in generative artificial intelligence are opening up new perspectives. One of the major benefits of Dataiku V13 is the ability to automatically generate recipes based on simple natural language instructions.
This novelty is not only intended to save time for technical users, it also makes it possible to give more autonomy to business profiles who do not necessarily have skills in development or advanced data manipulation.
Concretely, whereas previously creating a recipe required manual configuration step by step, it is now possible to describe the objective of the desired transformation in the form of a sentence in natural language. The AI then automatically generates an adapted recipe, ready to be previewed, modified if necessary, and then deployed in a few seconds.
A gain of time for experts, and new autonomy for business profiles.
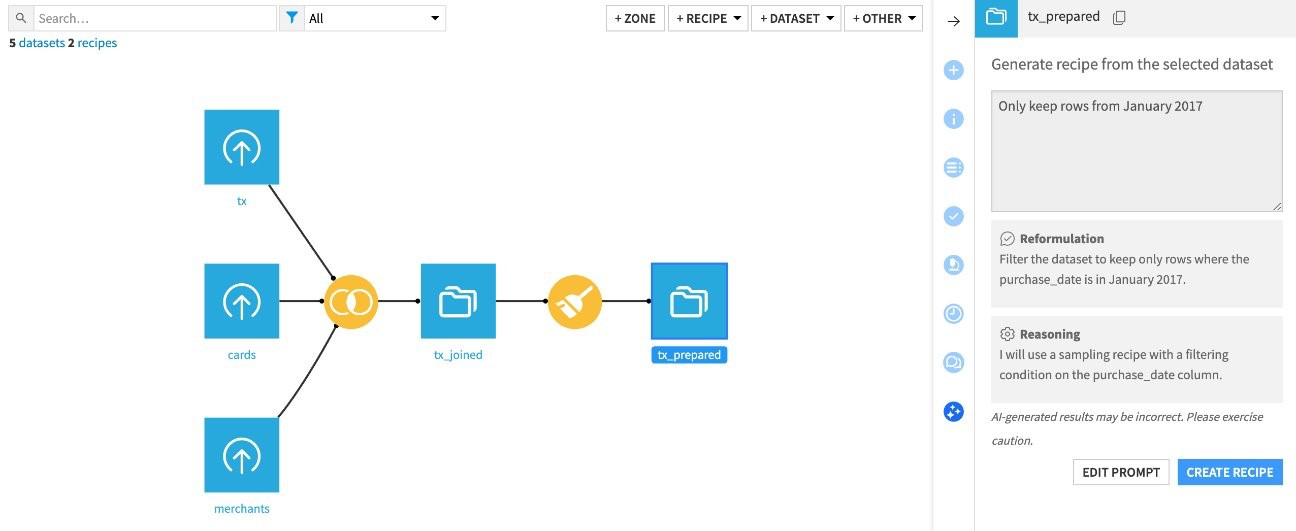
Interface to generate a visual recipe
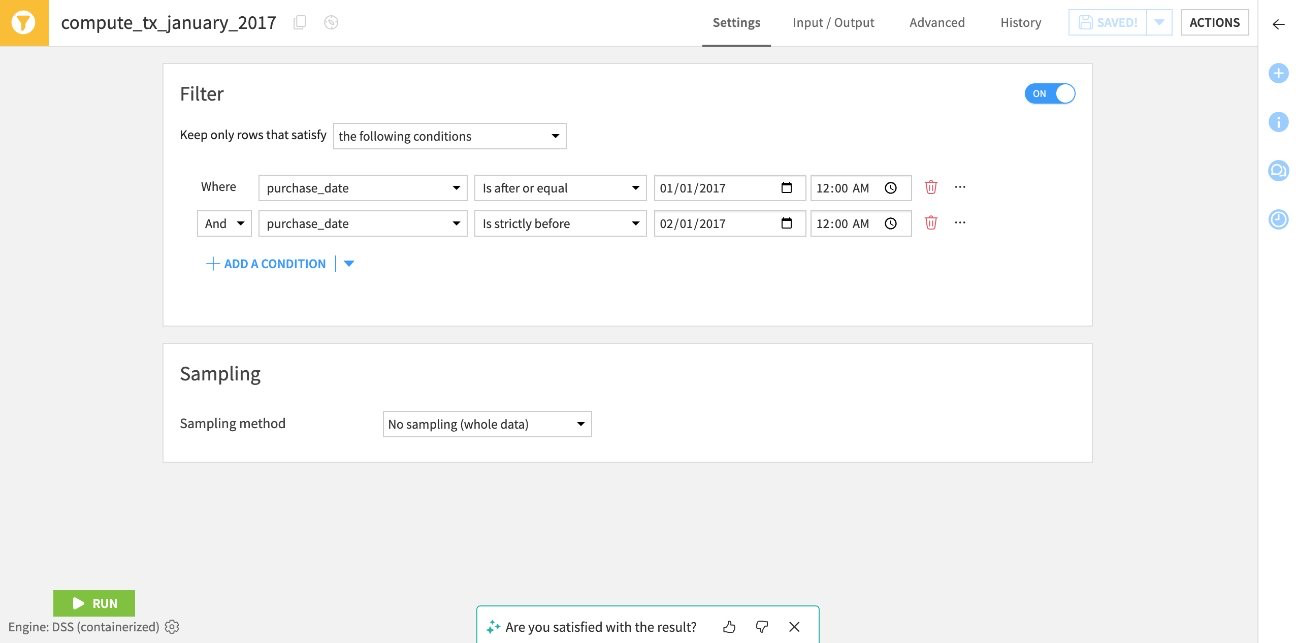
Result of the generation of the visual recipe
Link: https://doc.dataiku.com/dss/latest/release_notes/13.html#new-feature-ai-generate-recipe
In summary
With these new features, Dataiku further strengthens its position as a collaborative, robust and accessible platform, adapted to data projects that are increasing in complexity and demand.
At Eulidia, we already find these benefits with our customers:
- More peace of mind when working with others
- Fewer data quality risks
- A better understanding and transparency of treatments



.svg)
