
Depuis plusieurs années, Eulidia accompagne ses clients sur Dataiku, et voit passer de nombreuses mises à jour. Mais certaines font vraiment bouger les lignes. Avec la version 13, Dataiku a introduit des nouveautés qui améliorent concrètement la vie des équipes projet. Voici notre sélection (hors GenAI) des 4 avancées à ne pas rater.
Git merge dans l’interface : un vrai pas vers la collaboration fluide
Dataiku a toujours permis aux équipes pluridisciplinaires de collaborer facilement sur des projets data. Mais quand plusieurs personnes travaillent simultanément sur un projet DSS, ça peut vite être le chaos :
- On perd le fil des modifications, et il devient complexe d’identifier précisément qui a effectué quels changements, à quel moment et pour quelle raison
- On peut casser (sans le vouloir) un pipeline à cause d‘une mauvaise manipulation
- On écrase le travail de ses collègues. Si plusieurs contributeurs modifient en même temps les mêmes éléments, cela créer des conflits ou écrase le travail des autres.
Un système de version control dans Dataiku
Pour répondre à cette problématique, Dataiku intègre un système de version control basé sur Git. Il permet de tracer les modifications apportées (code, recettes, scénarios...) afin de faciliter la collaboration et de conserver un historique clair du projet.
Travailler sur une version stable et fonctionnelle du projet
Dans son utilisation principale, le version control permet de travailler sur une version stable et fonctionnelle du projet, tout en bénéficiant de branches de développement séparées de la branche principale, utilisées pour développer de nouvelles fonctionnalités dans un environnement safe.
Jusqu’à présent, il était possible de créer de nouvelles branches, mais pas de les fusionner. Mais avec la V13, on peut enfin gérer les merge directement dans l’interface, visualiser les conflits, les résoudre visuellement, et garder le contrôle.
Cas concret : un modèle de scoring pour fluidifier le projet data
Cas concret : Un modèle de scoring est déjà en production mais de nouvelles données métier sont désormais disponibles. L'équipe Data peut donc expérimenter un nouveau modèle de scoring avec l'ambition d'améliorer les métriques métier. Durant cette phase d'expérimentation, il est donc utile de travailler sur une version sécurisée décorrélée de la version en production afin de ne pas l'impacter (car on n'est pas certain que la nouvelle version soit meilleure que l'ancienne). Une fois le modèle validé, il peut alors être fusionné dans la branche principale directement depuis l’interface Dataiku.
Concrètement, cela permet de répondre aux principaux défis du travail collaboratif :
- Suivi des modifications : Chaque modification est historisée : on sait qui a changé quoi, quand, et pourquoi. Lors de chaque merge, un commentaire peut être ajouté pour documenter les choix effectués, ce qui améliore la compréhension collective du projet.
- Restauration en cas d’erreur : Une erreur dans une recette ? Un script supprimé par erreur ? Il est possible de revenir à une version stable précédente, qu’il s’agisse d’un objet, d’un fichier ou du projet entier.
- Conflits entre développeurs : Grâce au version control, chacun•e peut travailler sur une branche distincte, limitant les risques de conflits. Et s’il y a conflit, la résolution intégrée dans l’interface permet de le résoudre sans quitter Dataiku.
V13 de Dataiku : Ce qui change
Ce qui change donc avec la V13 :
- La gestion des merge depuis l’interface graphique
- La comparaison de deux branches et l'identification des différences
- La résolution des conflits de façon visuelle
- La gestion de la fusion de branche proprement, et sans avoir à passer par Git
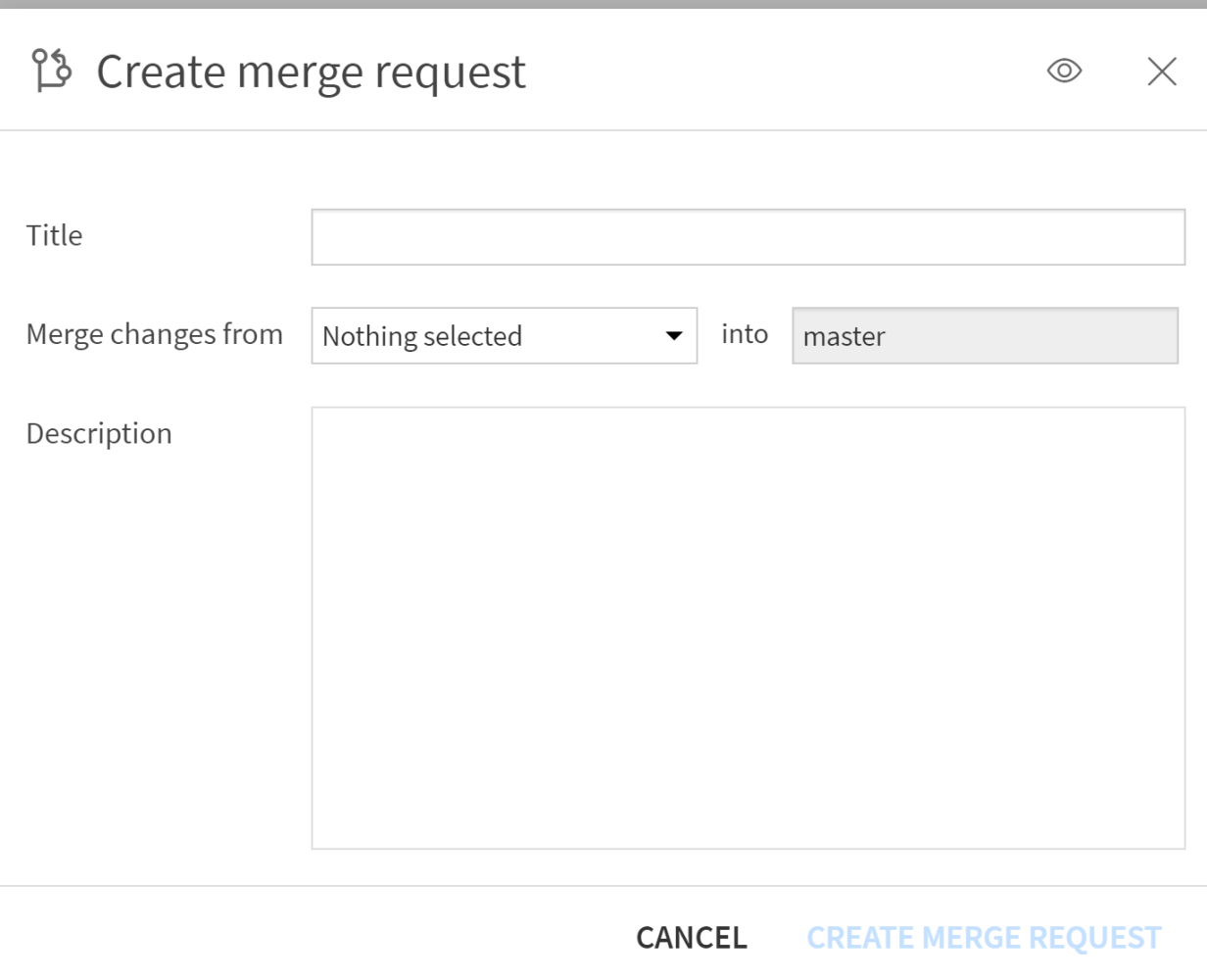

Avec cette nouveauté, Dataiku continue de renforcer sa posture de plateforme collaborative et accessible à tous les profils data. Une avancée bienvenue pour les équipes qui industrialisent leurs workflows analytiques à grande échelle.
Lien : https://doc.dataiku.com/dss/latest/release_notes/13.html#new-feature-builtin-git-merging
Data Quality : un prérequis indispensable pour tout projet data
Nous savons depuis longtemps que la qualité des données est à la base de la réussite de tout projet data. Sans données fiables, complètes et cohérentes, même les modèles les plus sophistiqués deviennent inefficaces. Une donnée erronée, et c’est toute votre analyse qui déraille. La qualité des données n’est pas un luxe, c’est un fondement.
La gestion centralisée et visuelle des règles de qualité via Dataiku V12.6
Dans sa V12.6, Dataiku introduit une gestion centralisée et visuelle des règles de qualité pour garantir des pipelines plus fiables et auditables.
En pratique, plusieurs situations peuvent poser problème :
- la qualité des données initiale est insatisfaisante
- les données peuvent changer (ajout de données dans un dataset etc..) et la qualité peut devenir insatisfaisante à l'issue des changements.
Exemple de données de qualité insatisfaisante à éviter
Des données de qualité insatisfaisante peuvent prendre différentes formes selon les cas.
Par exemple :
- Des valeurs manquantes sur des champs critiques, comme un identifiant client ou un code produit.
- Des valeurs incohérentes ou aberrantes, comme des dates de naissance situées dans le futur.
- Un taux de nullité anormalement élevé à la suite d’une jointure mal définie entre deux jeux de données.
Dataiku : Un mécanisme de suivi de la qualité des données
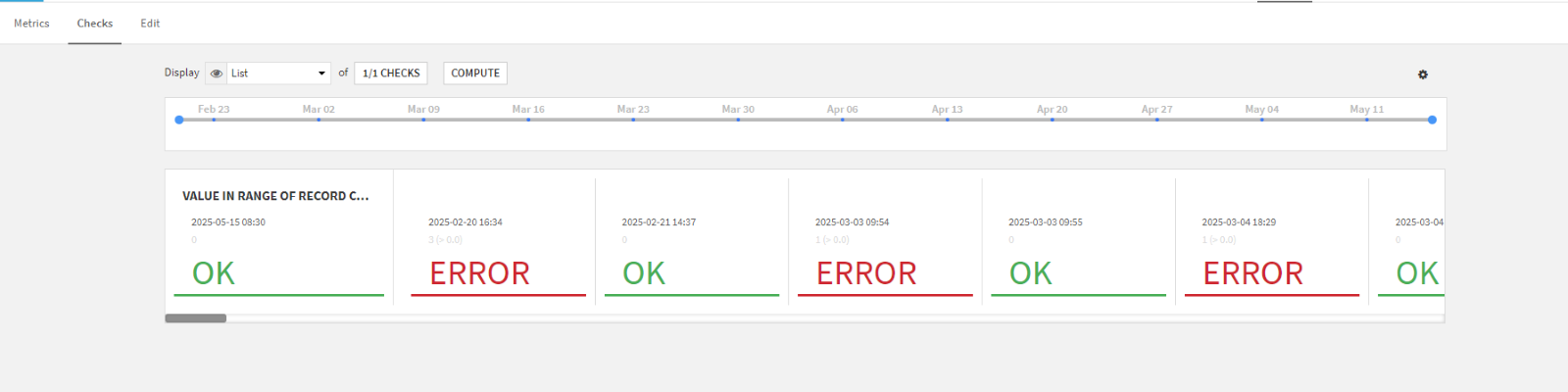
C'est pour répondre à cette problématique que Dataiku a implémenté un système de suivi de la qualité des données. Ce mécanisme permet de vérifier facilement que les données respectent des standards de qualité personnalisés, et de surveiller automatiquement leur état. Une règle de qualité des données teste si un jeu de données respecte certaines conditions définies.
Le statut résultant peut prendre une des valeurs suivantes :
✅ OK : la condition est respectée
⚠️ Warning : attention, un seuil est atteint
❌ Error : la règle est enfreinte
⭕ Empty : la condition n’a pas pu être évaluée
Avant cette version, le monitoring de la qualité des données se limitait à des metrics et checks définis individuellement au niveau de chaque dataset. Avec la V12.6, Dataiku introduit un module "Data Quality" directement intégré à l’interface des datasets.
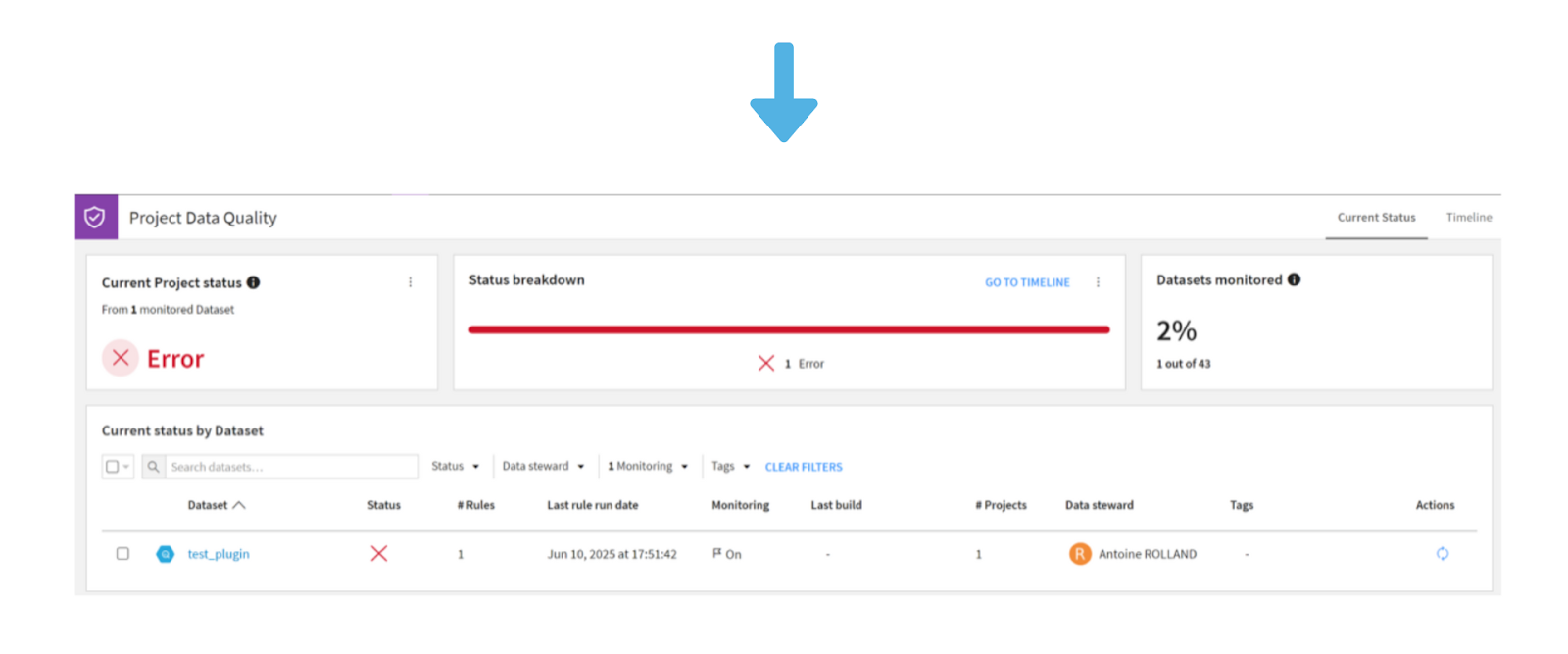
Autre évolution majeure : l’arrivée des Data Quality Templates. Ces modèles regroupent des ensembles de règles de qualité préconfigurées, que l’on peut appliquer facilement à plusieurs datasets. Ils sont globaux à l’instance DSS, ce qui permet à tous les utilisateurs de partager, réutiliser et standardiser les contrôles de qualité à l’échelle d’un projet.
Des évolutions qui simplifient le travail à grande échelle sur les projets data.
Lien : https://doc.dataiku.com/dss/latest/release_notes/12.html#data-quality
Data Lineage : pour une meilleure traçabilité des données dans vos projets
Dans un contexte où les pipelines de données deviennent de plus en plus complexes, la traçabilité des données n’est plus un luxe, mais une nécessité. Comprendre d’où viennent les données, comment elles ont été transformées, et quels data products sont impactés par une modification est devenu indispensable pour garantir la fiabilité et la transparence des traitements.
Les Risques d’une traçabilité non claire
Sans une traçabilité claire, plusieurs risques apparaissent :
- Manque de transparence sur les données
- Propagation des erreurs
- Incompréhension de l'impact des changements
C'est pour répondre à ces problématiques que Dataiku a implémenté un système de Data Lineage. Il permet de suivre l'évolution des données à travers un flux pour comprendre les évolutions/modifications subies.
Ça permet d’apporter des réponses aux problèmes précédents :
- Plus de transparence sur les données car il permet de visualiser le parcours complet de la donnée
- Moins de propagation des erreurs car le Data Lineage permet d’identifier rapidement toutes les entités impactées par une modification ou une erreur
- Moins d'incompréhension de l'impact des changements pour les mêmes raisons
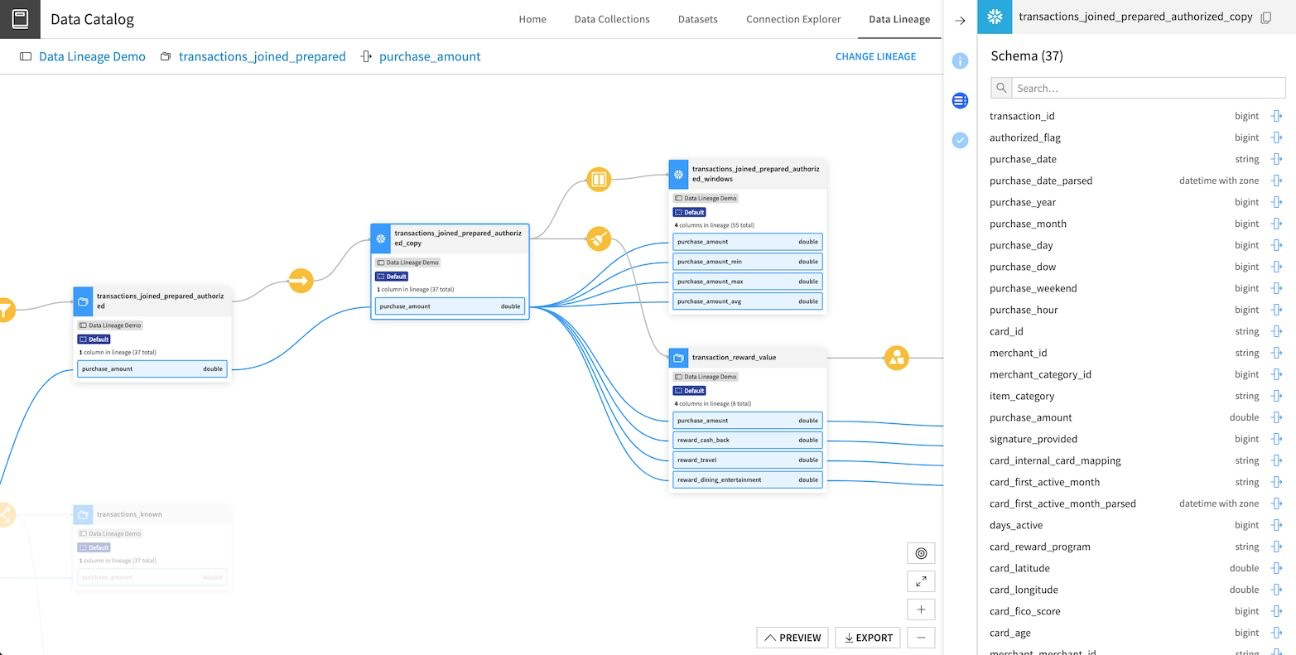
Attention tout de même, pour les recettes Python ou SQL, le lineage ne se génère pas automatiquement. Il faudra donc le définir manuellement afin qu’il puisse être correctement propagé dans le reste du flow.
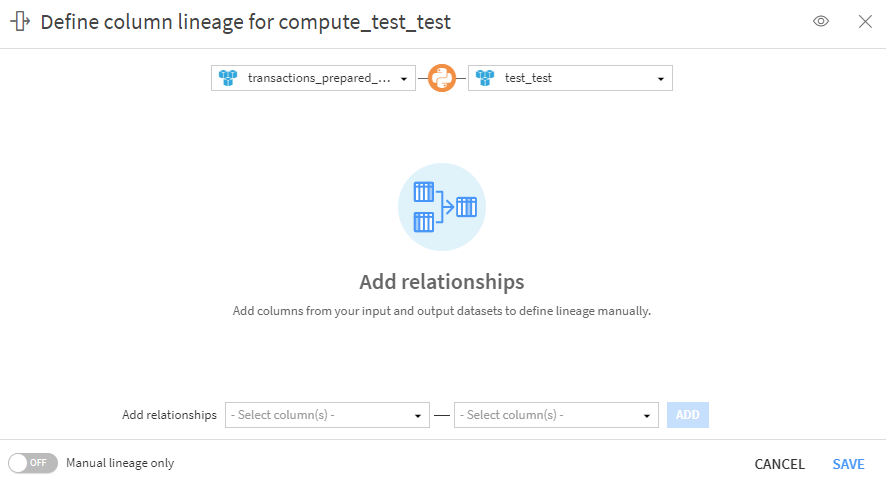
Lien : https://doc.dataiku.com/dss/latest/release_notes/13.html#new-feature-column-level-data-lineage
Création de recettes assistée par l'IA
Un gain de temps et plus d’autonomie pour les équipes
Dans un environnement où la rapidité d’exécution et la facilité de mise en œuvre sont des enjeux clés, les avancées en intelligence artificielle générative ouvrent de nouvelles perspectives. L’un des apports majeurs de la V13 de Dataiku est la possibilité de générer automatiquement des recettes à partir de simples instructions en langage naturel.
Cette nouveauté ne vise pas seulement à faire gagner du temps aux utilisateurs techniques, elle permet également de donner plus d’autonomie aux profils métiers qui n’ont pas nécessairement de compétences en développement ou en manipulation avancée de données.
Concrètement, alors qu’auparavant la création d’une recette nécessitait une configuration manuelle étape par étape, il est désormais possible de décrire l’objectif de la transformation souhaitée sous forme d’une phrase en langage naturel. L’IA génère alors automatiquement une recette adaptée, prête à être prévisualisée, modifiée si besoin, puis déployée en quelques secondes.
Un gain de temps pour les experts, et une autonomie nouvelle pour les profils métiers.
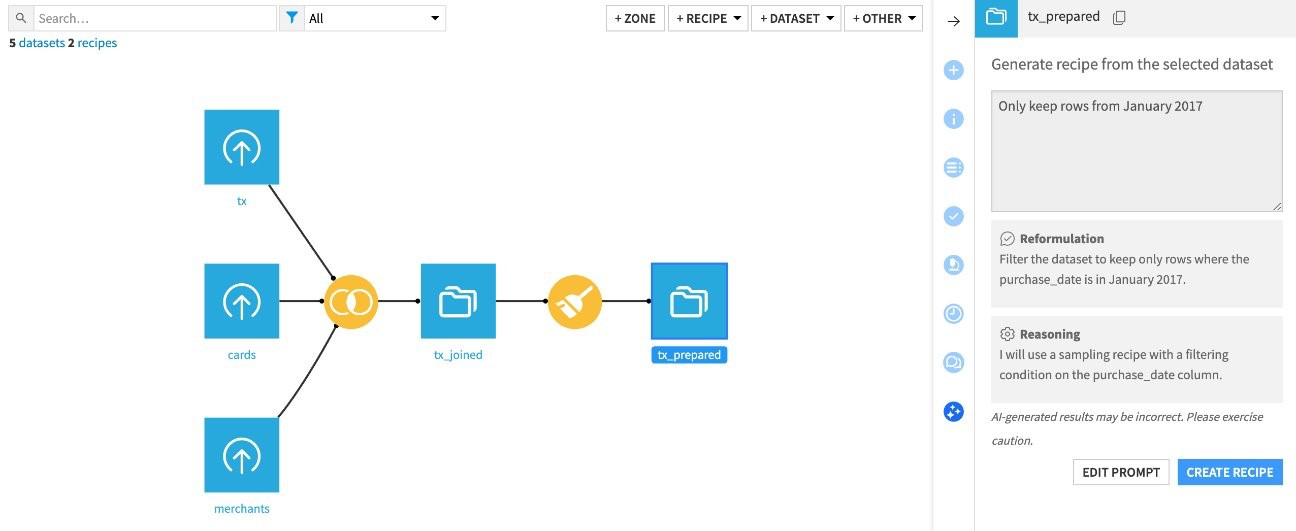
Interface pour générer une recette visuelle
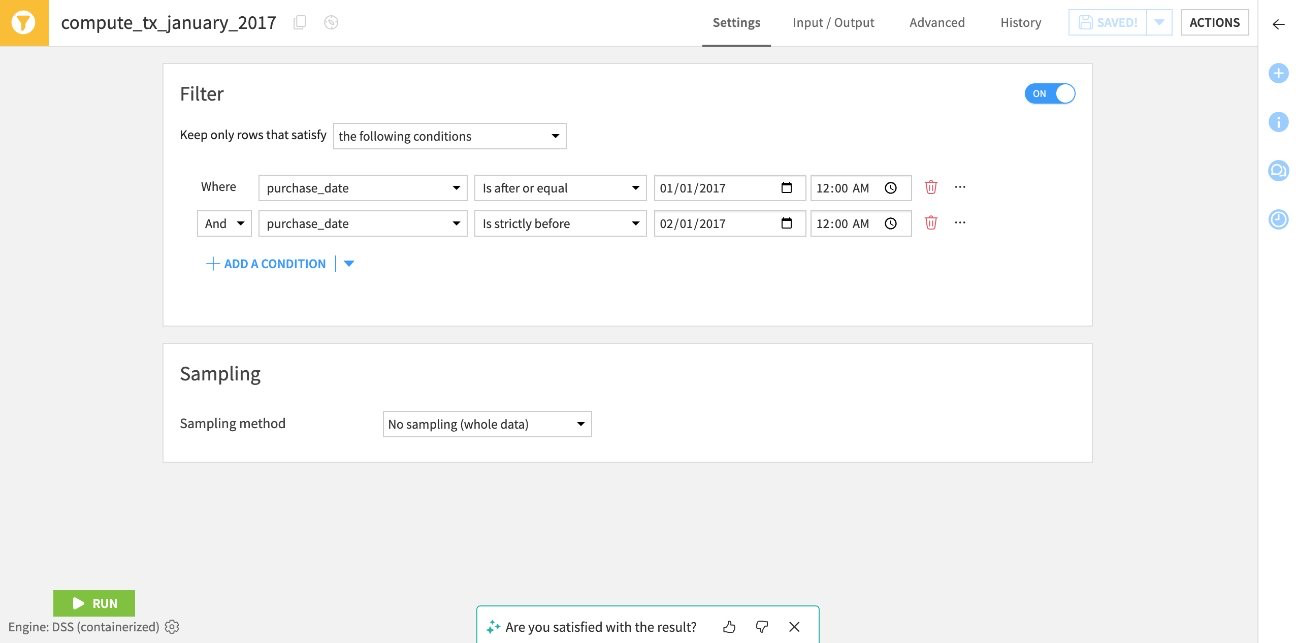
Résultat de la génération de la recette visuelle
Lien : https://doc.dataiku.com/dss/latest/release_notes/13.html#new-feature-ai-generate-recipe
En résumé
Avec ces nouveautés, Dataiku renforce encore sa position de plateforme collaborative, robuste et accessible, adaptée aux projets data qui montent en complexité et en exigence.
Chez Eulidia, on retrouve déjà ces bénéfices chez nos clients :
- Plus de sérénité dans le travail à plusieurs
- Moins de risques liés à la qualité des données
- Une meilleure compréhension et transparence des traitements



.svg)
