
Le coût de possession de l’IA ne se résume jamais au prix d’une API ou à celui d’un GPU. Il dépend surtout de la capacité de l’organisation à structurer une budgétisation IA, à maîtriser le passage à l’échelle et à piloter l’optimisation des LLM dans la durée. Les entreprises qui s’en sortent le mieux abordent cette thématique comme un sujet produit : gouverné, mesuré et industrialisé. C’est aussi l’approche défendue chez Eulidia, avec une ligne directrice simple : créer de la valeur mesurable, sans mauvaises surprises budgétaires.
Comprendre le TCO de l’IA: ce qui fait réellement grimper la facture
Lorsqu’un décideur évoque un projet d’IA ou de chatbot interne, la question clé n’est pas seulement ce que fait le modèle, mais pour combien d’utilisateurs, avec quels contenus, et quel niveau de risque accepté. Le TCO d’une IA, en particulier lorsqu’elle repose sur des LLM, est un empilement de postes. Les coûts des LLM les plus visibles comme les licences, le cloud ou les jetons masquent souvent des coûts moins apparents mais tout aussi structurants : données, sécurité, exploitation et conformité.
En pratique, trois postes reviennent systématiquement dans les environnements d’entreprise : l’infrastructure, les données et l’exploitation. Même un POC présenté comme rapide peut devenir coûteux si l’architecture d’inférence n’a pas été pensée pour la production. C’est souvent lors du passage du test au déploiement que les coûts IA se révèlent pleinement.
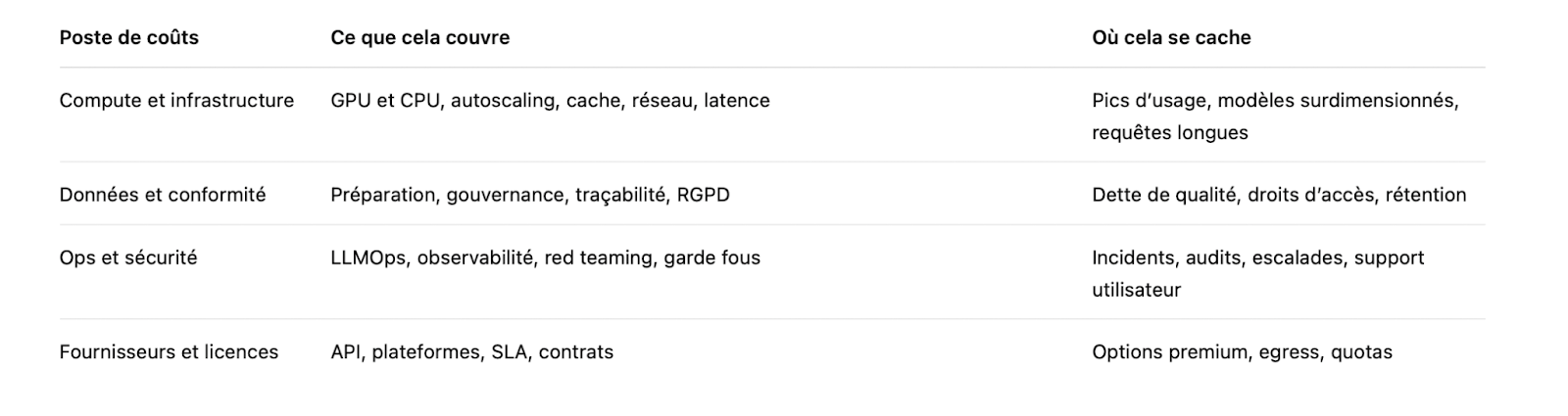
Sur le plan réglementaire, l’IA en entreprise s’inscrit dans un cadre européen précis. Le RGPD s’applique dès qu’il existe un lien avec des données personnelles, y compris de manière indirecte via les logs ou les prompts (Règlement UE 2016 679). L’AI Act, dans sa version publiée (Règlement UE 2024 1689), introduit quant à lui une approche par niveaux de risque et par cas d’usage. En clair, négliger la gouvernance revient souvent à payer deux fois, d’abord en coûts techniques, puis en coûts de mise en conformité.
Compute et infrastructure : la facture souvent sous-estimée des LLM
Le coût d’inférence ne dépend pas uniquement du volume de requêtes. Il est fortement influencé par les choix de conception. Des réponses inutilement longues, des contextes surchargés ou l’absence de mécanismes de cache entraînent une consommation excessive de jetons. À grande échelle, quelques secondes de latence supplémentaires suffisent à augmenter significativement la capacité nécessaire. Les charges en temps réel, par ailleurs, imposent des architectures plus coûteuses que des traitements batch.
C’est dans ce contexte que les pratiques FinOps prennent tout leur sens, y compris pour l’IA. Le FinOps Foundation rappelle que l’enjeu n’est pas seulement de réduire la facture, mais d’arbitrer en permanence entre coût et performance afin de maximiser le ROI de l’IA (FinOps Framework). Appliqué aux LLM, cela signifie choisir une architecture adaptée aux usages réels, ajuster les modèles au juste besoin et éviter le surdimensionnement par précaution.
Budgétisation : chiffrer par cas d’usage, pas « au feeling »
Une budgétisation IA efficace commence par une question très concrète : combien de décisions, de documents ou de conversations sont traités chaque mois. À partir de là, on ajoute la criticité des usages, les exigences de sécurité et les contraintes d’intégration au SI existant. Cette approche, orientée cas d’usage, permet de prioriser ce qui génère un impact réel et mesurable, avant d’envisager un passage à l’échelle plus large. Elle s’inscrit pleinement dans une logique de data stratégie pilotée par la valeur.
En entreprise, trois erreurs reviennent fréquemment.
La première consiste à budgéter par projet, sans intégrer le run, alors que l’IA doit être pensée comme un produit vivant. La deuxième est d’ignorer les coûts liés aux données : nettoyage, indexation, droits d’accès et gouvernance. La troisième est de sous-estimer les coûts d’accompagnement, notamment la formation, l’adoption par les équipes et le support utilisateur. Le scénario est connu : un budget est validé pour un POC, puis l’organisation se retrouve à bricoler au moment du passage en production, avec des coûts IA mal maîtrisés.
Build ou buy, cloud ou on-premise : les arbitrages réels
Le débat entre build et buy est rarement binaire. Il est souvent pertinent d’acheter certaines briques, de personnaliser les couches différenciantes et de conserver la gouvernance en interne. Le cloud permet d’accélérer le time to value, mais introduit des coûts variables et une dépendance aux fournisseurs. L’on-premise peut rassurer sur les sujets de souveraineté, mais implique des compétences spécifiques, des investissements matériels et des cycles d’achat plus longs.
Les modèles de tarification méritent également une attention particulière. Certains acteurs facturent au jeton, en entrée et en sortie, d’autres à la requête, au siège ou via des engagements de volume. Pour piloter les coûts, il est plus pertinent de ramener ces modèles à un coût unitaire par scénario métier. Un coût par document traité, par ticket support ou par résumé validé est souvent bien plus parlant pour une décision managériale qu’un tableau de prix brut, surtout lorsque l’on analyse les coûts des LLM sur la durée.
Mini checklist budgétaire : simple, mais efficace
Avant de valider un budget IA, certains points doivent être posés clairement. Ils permettent d’éviter la majorité des mauvaises surprises et de sortir des arbitrages purement intuitifs.
- Définir un coût cible par cas d’usage, avec une unité métier explicite.
- Fixer un niveau de qualité attendu, y compris un taux d’erreur acceptable.
- Mesurer la latence maximale tolérée en production, en particulier pour les usages temps réel.
- Intégrer le run dès le départ : monitoring, sécurité, support et mises à jour des modèles.
- Prévoir une enveloppe d’optimisation trimestrielle pour améliorer le coût unitaire et soutenir l’optimisation des LLM.
Cette discipline budgétaire est un prérequis pour sécuriser le ROI de l’IA et éviter que la phase d’industrialisation ne se transforme en zone de turbulences.
Passage à l’échelle : industrialiser l’IA sans explosion des coûts
Le passage à l’échelle ne se résume pas à une question de volume. Il s’agit d’un véritable changement de régime : davantage d’utilisateurs, plus de données, plus d’intégrations et, mécaniquement, plus de risques. S’ajoute à cela une variabilité accrue des prompts et des comportements. Sans garde-fous clairs, un agent mal cadré peut entrer dans une boucle coûteuse et consommer un budget significatif en quelques heures. Ce scénario n’a rien de théorique.
Dans une trajectoire de transformation data, l’industrialisation repose sur trois fondamentaux : une responsabilité clairement définie, des métriques partagées et une capacité à déployer sans fragiliser l’existant. Sur le plan technique, cela implique une architecture d’inférence capable d’absorber les pics de charge, de lisser les usages et de prioriser les requêtes critiques. C’est une condition essentielle pour maîtriser durablement les coûtsRAG, fine tuning ou agents : choisir l’approche la plus rentable.
Pour de nombreuses organisations, le RAG constitue le point d’entrée le plus pertinent. En s’appuyant sur des sources internes validées, il limite les hallucinations et évite un réentraînement lourd des modèles.
Le principe du RAG s’appuie sur l’idée d’un accès à une mémoire externe, formalisée dès les premiers travaux académiques (Lewis et al., 2020).
Si ces travaux posent le cadre conceptuel, les architectures actuelles ont largement évolué pour répondre aux enjeux de passage à l’échelle, de performance et de gouvernance.
Le fine tuning peut devenir rentable dans des contextes spécifiques, notamment pour des tâches répétitives et stables. Il suppose toutefois une hygiène de données rigoureuse, un jeu d’entraînement de qualité et un cycle de validation clair. Sans cela, les gains attendus sont rapidement absorbés par des coûts de maintenance.
Les agents, enfin, offrent un potentiel d’automatisation élevé, mais ils augmentent fortement la variabilité des usages. Cette variabilité se traduit directement par une hausse des coûts. La règle reste simple : recourir aux agents lorsque le gain opérationnel est clairement identifié et lorsque les boucles, les outils et les permissions sont strictement contrôlés. À défaut, l’organisation finance une démonstration séduisante, mais hérite d’un run complexe et instable.
Architecture d’inférence : autoscaling, cache et files d’attente
Pour soutenir le passage à l’échelle sans dégrader les performances ni le budget, plusieurs leviers sont généralement combinés : autoscaling, files d’attente, batching et mécanismes de cache. Le cache reste souvent sous-estimé, alors qu’il permet de réduire significativement les requêtes répétées et d’améliorer les temps de réponse. Les files d’attente jouent un rôle clé pour protéger les systèmes lors des pics d’usage, tandis que le batching amortit les coûts GPU, en particulier pour les traitements hors temps réel.
L’observabilité constitue enfin un pilier central. Sans mesure, il n’y a pas de pilotage possible. Dans des environnements appuyés sur des cloud technologies, il devient possible d’instrumenter finement la latence, la consommation de jetons et les taux d’erreur. Ces indicateurs permettent d’ajuster en continu les paramètres et de soutenir une optimisation des LLM compatible avec les objectifs de ROI de l’IA.
Optimisation des LLM : réduire les coûts sans dégrader les performances
L’optimisation des LLM est souvent le levier le plus rentable après un cadrage initial solide. La raison est simple : une amélioration marginale du prompt, du routage ou du choix de modèle se réplique sur des milliers de requêtes. À cette échelle, la réduction des coûts des LLM devient mécanique. L’objectif n’est pas de faire moins cher à tout prix, mais de dépenser au bon endroit, en réduisant le gaspillage sans compromettre la qualité.
Le premier réflexe consiste à choisir la bonne taille de modèle. Un grand LLM n’est pas nécessaire pour tous les usages. Pour du tri, de la classification ou de l’extraction, des modèles plus légers offrent souvent un excellent compromis, en particulier lorsque la donnée est bien structurée. Les modèles plus puissants doivent être réservés aux cas de raisonnement complexe, et mobilisés uniquement lorsque la valeur métier le justifie. Cette logique est centrale pour piloter durablement les coûts.
Routage par complexité : léger par défaut, escalade si nécessaire
Le routage agit comme une boîte de vitesses. Par défaut, le système s’appuie sur un modèle rapide et économique. Lorsque la requête dépasse un seuil défini, complexité, sensibilité ou incertitude, elle est automatiquement escaladée vers un LLM plus performant. Ce schéma permet de réduire significativement les dépenses sans dégrader l’expérience utilisateur, à condition de calibrer finement les seuils et les tests qualité.
Les prompts jouent ici un rôle déterminant. Des prompts trop longs, trop vagues ou construits par simple copie de documents entiers entraînent une surconsommation de jetons. À l’inverse, résumer, structurer l’information, utiliser des templates et limiter le contexte permet d’optimiser l’usage des tokens et de stabiliser le comportement du modèle. Dans de nombreuses équipes, l’effet est immédiat : le coût unitaire par requête diminue, tout en réduisant le bruit et les réponses inutiles.
Personnaliser sans tout réentraîner : LoRA, distillation et tuning ciblé
Adapter un modèle de langage ne signifie pas repartir de zéro. Des techniques comme LoRA permettent de spécialiser un LLM en n’entraînant qu’une fraction des paramètres, plutôt que l’ensemble du réseau, comme décrit par Hu et al. Cette approche est généralement plus rapide, plus contrôlable et mieux alignée avec une exploitation industrielle à grande échelle.
À ces méthodes s’ajoutent d’autres leviers d’optimisation, comme la quantification, le batching, l’arrêt anticipé ou le streaming côté inférence. Ils permettent de réduire la latence et les coûts, en particulier dans des contextes de passage à l’échelle. Un point reste toutefois central : chaque optimisation doit être évaluée à l’aune de son impact sur la qualité. Une baisse de performance se traduit rapidement par des coûts indirects, rework, support et perte de confiance, qui annulent les gains initiaux.
Pilotage : suivre les coûts, la qualité et la rentabilité dans la durée
Une IA en entreprise n’est jamais un dispositif « installé puis oublié ». Les usages évoluent, les documents changent, les modèles sont mis à jour. Les coûts suivent le même mouvement. Le pilotage doit donc relier trois dimensions indissociables : les coûts unitaires, la qualité délivrée et la rentabilité. Et ce pilotage doit vivre dans un tableau de bord lisible et partagé, pas dans un fichier Excel figé qui ne sert qu’une fois par trimestre.
Pour structurer cette démarche, de nombreuses organisations s’appuient sur un cadre de gestion des risques éprouvé. Le NIST propose un référentiel particulièrement utile pour organiser la gouvernance, la mesure et les contrôles, y compris pour des systèmes d’IA générative (NIST AI RMF). En Europe, ce cadre est ensuite croisé avec les exigences du RGPD et de l’AI Act, en fonction des cas d’usage et des niveaux de risque. Cette articulation permet d’aligner pilotage opérationnel et conformité réglementaire, sans multiplier les dispositifs parallèles.
Un socle de KPI pragmatiques pour piloter dans la durée
Pour tenir dans le temps, le pilotage doit s’appuyer sur des indicateurs simples, compréhensibles et actionnables. Voici un socle de KPI fréquemment utilisé en comité de pilotage, à adapter selon les contextes, mais suffisamment robuste pour démontrer une création de valeur répétable, du cadrage au run.
- Coût par requête et coût par document, avec une ventilation claire entre jetons, infrastructure et exploitation.
- Coût par utilisateur actif et par équipe, assorti de quotas explicites.
- Latence (P95) et taux de timeouts, afin de mesurer la stabilité des temps de réponse et l’expérience utilisateur, en particulier pour les usages temps réel.
- Taux de réussite, taux de fallback et taux d’hallucinations signalées ou suspectées.
- Taux d’escalade vers un modèle plus puissant, avec une analyse des causes.
- Incidents de sécurité, dérives de données et indicateurs de conformité liés aux logs, à la rétention et aux droits d’accès.
Ces indicateurs permettent de piloter à la fois les coûts des LLM, la qualité de service et le ROI de l’IA, sans tomber dans une logique purement financière ou, à l’inverse, exclusivement technique.
La discipline comme avantage compétitif
Au-delà des métriques, la différence se fait souvent sur la discipline opérationnelle. Audits réguliers des prompts, A/B tests avant et après optimisation, chasse systématique aux tokens inutiles et comparaison des fournisseurs sur le coût effectif, et non sur le tarif catalogue. Ces pratiques permettent de maintenir une trajectoire saine dans le pilotage des coûts de l’IA.
Une seule fonctionnalité mal configurée peut, à elle seule, coûter plus cher que le modèle sous-jacent. C’est là que le pilotage prend tout son sens. Dans la durée, ce sont les détails qui font la différence entre une IA maîtrisée et une IA qui dérive silencieusement.
Conclusion
Maîtriser le coût de possession de l’IA en 2026 ne consiste pas à traquer chaque centime. Il s’agit avant tout de structurer une budgétisation IA par cas d’usage, d’orchestrer un passage à l’échelle maîtrisé et d’inscrire l’optimisation des LLM et de l’inférence dans une logique continue. Les organisations qui réussissent abordent le pilotage des coûts de l’IA comme un actif stratégique : gouverné, mesuré, sécurisé et amélioré dans la durée. Cette approche permet de réduire les dépenses superflues tout en préservant, voire en renforçant, la valeur métier.
S’il ne fallait retenir qu’un principe, ce serait celui ci : commencer petit, tout mesurer et n’industrialiser que ce qui démontre un ROI de l’IA réel et reproductible. Le reste génère surtout du bruit opérationnel… et des coûts difficiles à justifier.
FAQs
Comment optimiser les coûts d’utilisation des jetons pour les LLM ?
Pour optimiser les coûts liés à l’utilisation des jetons avec les LLM, il convient d’agir à plusieurs niveaux. La première étape consiste à réduire la longueur des requêtes et des réponses, à limiter le contexte aux informations réellement utiles et à mettre en cache les réponses fréquentes. Il est également recommandé d’utiliser des modèles plus légers pour les tâches simples. Une bonne gestion des prompts et un choix adapté des modèles permettent de réduire les coûts sans dégrader les performances ni les temps de réponse. Le pilotage repose enfin sur des indicateurs clairs, comme le coût par requête ou le coût par utilisateur.
Comment intégrer un pilotage par l’IA pour améliorer la rentabilité ?
Mettre en place un pilotage par l’IA consiste à orchestrer les applications LLM, les systèmes multi agents et les modèles de machine learning afin d’automatiser les tâches à faible valeur ajoutée. En personnalisant les prompts, en routant les requêtes vers les modèles les plus adaptés et en combinant des architectures hybrides, local et cloud, les organisations optimisent les coûts d’utilisation tout en améliorant la performance globale. Cette approche permet de réduire les charges d’infrastructure et d’offrir des temps de réponse plus stables aux utilisateurs.
Quels sont les leviers pour optimiser les performances des LLM dans les applications temps réel ?
Pour les usages temps réel, l’optimisation passe par le choix de modèles plus rapides ou quantifiés, la mise en place de mécanismes de batching et l’utilisation de caches et d’index de données pertinents. Ces leviers permettent de réduire la latence tout en maintenant un niveau de qualité adapté aux attentes métier. Une performance maîtrisée améliore directement la satisfaction des utilisateurs et la rentabilité des solutions basées sur l’IA.
Comment les modèles plus petits permettent-ils de réduire les coûts et la latence ?
Les modèles plus petits consomment moins de jetons et mobilisent moins de ressources de calcul, ce qui réduit les coûts d’infrastructure. En adaptant la taille du modèle à la complexité de la tâche et en recourant à des techniques comme la distillation ou la quantification, il est possible d’obtenir des temps de réponse plus courts et des économies significatives. Cette approche permet de maîtriser les coûts des LLM sans sacrifier les fonctionnalités essentielles.
Comment gérer efficacement les coûts d’utilisation des architectures hybrides ?
La gestion des coûts dans des architectures hybrides repose sur une hiérarchisation claire des charges de travail. Les tâches critiques ou complexes sont confiées à des modèles plus puissants, tandis que les tâches routinières sont traitées par des modèles plus légers. En combinant cette approche avec une gestion fine des jetons, des mécanismes de mise en cache, une personnalisation des prompts et une surveillance continue des indicateurs clés, il devient possible de réduire les coûts tout en améliorant la qualité des réponses.
Quelles sont les bonnes pratiques pour optimiser les requêtes et réduire les coûts associés aux LLM ?
Les bonnes pratiques incluent la conception de prompts concis, l’utilisation de stop sequences pour limiter la génération de jetons, la réutilisation de contextes pertinents et la mise en place de filtres en amont pour éviter les requêtes inutiles. Ces actions contribuent à réduire significativement les coûts tout en améliorant les performances et la qualité des décisions prises à partir des applications LLM.
Comment mesurer les économies de coûts et la rentabilité lors de l’optimisation des LLM ?
La mesure des économies repose sur des métriques simples et actionnables : coût par requête, coût par utilisateur, latence moyenne, taux d’échec et gains de productivité. Ces indicateurs doivent être croisés avec les usages réels afin d’évaluer la rentabilité des optimisations mises en place. Une approche fondée sur les données permet d’itérer efficacement sur les modèles et les flux de travail, garantissant des économies durables et un ROI maîtrisé.



.svg)
