
Introduction
Une architecture BI moderne sert avant tout à une chose essentielle : mieux décider, plus vite, avec moins d’incertitude. Elle ne remplace pas la business intelligence existante. Elle la modernise, pour absorber des volumes de données croissants, intégrer le temps réel et préparer l’usage de l’IA, sans explosion des coûts ni accumulation de dette technique.
Concrètement, on ne parle plus simplement d’un entrepôt de données cloud connecté à quelques rapports. On évolue vers une plateforme de décision capable d’aligner données, usages métiers et exigences de sécurité dans une même business intelligence architecture cohérente.
Et c’est souvent là que le déclic se produit.
Dans de nombreux grands groupes, les équipes ne veulent plus « attendre le prochain refresh ». Elles attendent des indicateurs fiables, des tableaux de bord cohérents et une analyse de données capable de servir à la fois Power BI, les outils analytiques avancés et les modèles d’IA. Chez Eulidia, nous observons régulièrement cette tension : accélérer l’analytique sans renoncer à une gouvernance des données solide.
C’est précisément là qu’intervient le BI architecture framework moderne. Il accepte la diversité des sources, des outils et des usages, mais impose une logique claire : centraliser ce qui doit l’être, automatiser les pipelines, structurer le sens des données. Le tout en s’appuyant sur des fondations comme le data lake et lakehouse, sans retomber dans une complexité inutile.
Au fond, la modernisation de la BI n’est pas un simple projet technique. C’est un changement de posture. Une architecture BI moderne se conçoit, se pilote et s’améliore comme un produit, au service de la décision, et non comme un chantier ponctuel que l’on referme une fois livré.
Business intelligence architecture : la BI moderne, côté terrain
La business intelligence architecture ne se résume plus à une question d’outils ou de technologies. Elle structure la manière dont une organisation transforme ses données en décisions, au quotidien. À mesure que les usages se diversifient et que les attentes métiers augmentent, l’architecture BI devient un véritable levier de performance. Mais encore faut-il comprendre ce qui distingue une architecture BI moderne d’un empilement de briques techniques, et comment elle s’ancre concrètement dans la réalité du terrain.
Définition et vision globale
Une business intelligence architecture moderne n’est pas un schéma élégant posé sur une slide de comité de pilotage. C’est une organisation vivante de composants ingestion, stockage, traitement, couche sémantique, visualisation qui permet de transformer des données brutes en décisions réellement exploitables.
Le point clé est souvent sous-estimé. Une architecture BI moderne doit traiter des flux de données à grande échelle tout en garantissant la qualité, la traçabilité et la sécurité. Sans ces fondations, la plateforme devient vite instable. Et une plateforme instable ne produit jamais de bonnes décisions.
Autrement dit, l’architecture n’est pas un objectif en soi. Elle est au service d’une plateforme de décision capable de soutenir les usages métiers dans la durée.
Les principes qui changent vraiment la donne
Lorsqu’on observe les architectures BI modernes qui fonctionnent sur le terrain, trois principes reviennent systématiquement.
D’abord, la modularité. Fini les monolithes rigides, difficiles à faire évoluer. Une architecture BI moderne repose sur des briques interchangeables, capables d’évoluer indépendamment.
Ensuite, la scalabilité. Les volumes de données augmentent, les usages se multiplient. Cela ne doit plus être une source de stress, mais une hypothèse de départ du BI architecture framework.
Enfin, l’automatisation. Les pipelines de données doivent s’exécuter de manière fiable, être supervisés en continu et déclencher des mécanismes d’alerte, de reprise et de remédiation partielle, avec un minimum d’intervention humaine. Sans cela, la dette opérationnelle s’accumule aussi vite que la dette technique.
Ces principes ne sont pas théoriques. Ils conditionnent directement la capacité de l’architecture à tenir dans le temps.
D’une BI descendante à une BI orientée produit de données
Pendant longtemps, la BI a fonctionné de manière descendante. Des équipes centralisées produisaient des rapports standards pour un nombre limité de décideurs. Mais ce modèle atteint vite ses limites.
Aujourd’hui, les métiers veulent explorer, segmenter, tester. Ils attendent des capacités de self service BI, des modèles réutilisables et des couches sémantiques partagées. L’objectif est clair : réduire la distance entre “j’ai une question” et “j’ai une réponse”.
C’est ici que la logique de produit de données prend tout son sens. Les données ne sont plus simplement livrées. Elles sont conçues pour être comprises, utilisées et réutilisées.
Ce que le cloud change, concrètement
Le cloud ne résout pas tout, mais il transforme profondément l’économie de la BI. Il permet de découpler le stockage et le calcul, d’ajuster la puissance à la demande et de mieux intégrer les usages temps réel.
C’est aussi ce qui rend possibles des architectures plus distribuées, combinant traitements par lots, flux continus, microservices et parfois serverless. Résultat : une BI plus élastique, capable de s’adapter aux pics d’usage comme aux phases plus calmes.
Dans ce contexte, l’entrepôt de données cloud n’est plus une fin en soi, mais un composant clé au sein d’un ensemble plus large.
En quoi c’est différent d’une architecture traditionnelle
La rupture la plus visible concerne le passage de l’ETL à l’ELT. On charge les données rapidement, puis on les transforme au plus près des moteurs analytiques. Ce changement améliore la performance et simplifie l’exploitation.
Autre différence majeure : le découplage stockage calcul, qui évite de surdimensionner une infrastructure pour des requêtes ponctuelles. On paie pour l’usage réel, pas pour un maximum théorique.
Enfin, on observe une décentralisation maîtrisée des responsabilités, portée par des approches comme la data mesh et une gouvernance partagée. L’architecture reste cohérente, mais les équipes gagnent en autonomie.
C’est cette combinaison qui permet à une architecture BI moderne de passer du concept à l’impact métier réel.
Entrepôt de données cloud : socle robuste, même à l’ère du lakehouse
À l’heure où les architectures lakehouse gagnent en visibilité, la place de l’entrepôt de données est souvent questionnée. Faut-il encore s’appuyer sur un data warehouse dans une architecture BI moderne, ou repenser entièrement le socle décisionnel ? Avant de trancher, il est utile de revenir à un point fondamental : les usages réels de la BI sur le terrain.
L’entrepôt est-il encore nécessaire ?
La réponse est oui, dans la grande majorité des cas.
Un entrepôt de données cloud reste aujourd’hui le socle le plus fiable pour la BI structurée : données financières, référentiels métiers, KPI officiels, reporting réglementaire. Il apporte ce que les organisations recherchent souvent en priorité : performance, cohérence et stabilité.
Lorsqu’un COMEX demande une vision consolidée et incontestable, ce n’est pas un jeu de données expérimental qu’il attend, mais une version de la vérité clairement définie. Dans ce rôle précis, le data warehouse demeure un allié solide de toute architecture BI moderne, y compris dans des environnements plus hybrides intégrant data lake et lakehouse.
Comment l’entrepôt s’insère dans une architecture BI moderne
Dans une architecture BI moderne, l’entrepôt n’est plus un silo isolé. Il s’intègre dans un écosystème plus large, connecté aux sources opérationnelles, aux flux de données temps réel et, selon les cas, à un data lake ou un lakehouse.
Les pipelines ELT permettent de charger rapidement les données, puis de les transformer au plus près des moteurs analytiques. Les mises à jour deviennent incrémentales, les contrôles de qualité systématiques, et les dépendances plus lisibles. L’objectif n’est pas de tout centraliser aveuglément, mais de stabiliser ce qui doit l’être, tout en laissant de la flexibilité ailleurs.
C’est cette articulation intelligente qui évite de transformer l’entrepôt en goulot d’étranglement.
Ingestion : batch, temps réel et zones de confiance
Pour maîtriser la complexité, de nombreuses équipes structurent leurs données en zones de confiance. Le modèle bronze, silver, gold s’impose progressivement comme une bonne pratique.
La zone bronze accueille les données brutes, telles qu’elles arrivent. La zone silver contient des données nettoyées, conformes et enrichies. La zone gold expose les jeux de données prêts pour la BI, les tableaux de bord et les indicateurs officiels.
Cette organisation facilite la gestion des flux batch et temps réel, améliore la traçabilité des transformations et limite les mauvaises surprises côté utilisateurs. Elle contribue aussi à rendre l’architecture plus lisible, tant pour les équipes techniques que métiers.
Modélisation et gouvernance : ce qui évite les débats sans fin
Côté modélisation, les schémas en étoile restent particulièrement efficaces pour l’analytique et les bases décisionnelles. Dans des contextes où les sources évoluent fréquemment ou où la traçabilité est critique, des approches comme Data Vault peuvent s’avérer pertinentes.
Mais le véritable sujet dépasse le choix du modèle. Sans gouvernance des données, aucune architecture ne tient longtemps. Catalogage, lineage, règles de qualité, définitions partagées des indicateurs : ce sont ces mécanismes qui transforment un entrepôt de données cloud en véritable plateforme de décision.
Sans eux, même la meilleure architecture BI moderne finit par ressembler à une tour de Babel.
Data lake et lakehouse : l’agilité sans perdre le contrôle
À mesure que les architectures BI se modernisent, la question du socle analytique refait systématiquement surface. Faut-il privilégier la stabilité d’un entrepôt de données cloud, la flexibilité d’un data lake, ou chercher un équilibre entre les deux ? C’est précisément dans cette zone de tension que s’inscrivent les approches lakehouse.
Data lake vs data warehouse : une comparaison utile, pas un duel
Le data lake est pensé pour accueillir des données brutes, hétérogènes et parfois semi structurées, avec un haut niveau de flexibilité. Le data warehouse, de son côté, vise avant tout la fiabilité, la performance et la standardisation des données structurées.
Dans une architecture BI moderne, l’enjeu n’est plus d’opposer ces deux modèles. La plupart des organisations les combinent, chacune répondant à des usages bien distincts. Lorsque le besoin d’unification se fait sentir, la trajectoire conduit naturellement vers le lakehouse, conçu comme un point de convergence plutôt qu’un remplacement brutal.
Pour clarifier les rôles, une comparaison par usage reste souvent plus parlante qu’un débat théorique.
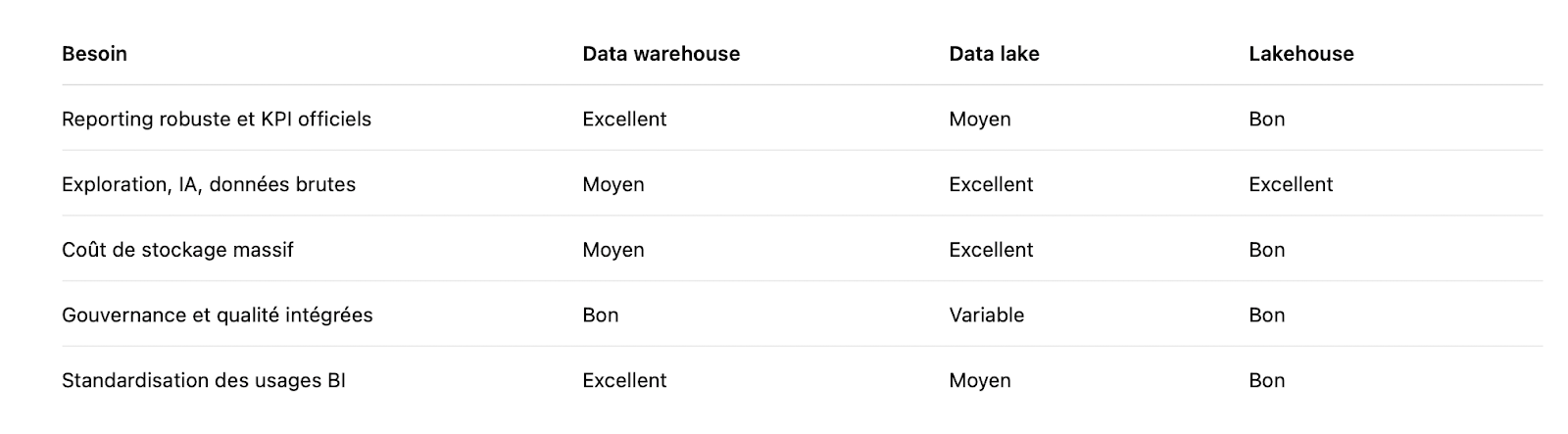
Cette lecture met en évidence un point clé : la valeur ne vient pas d’un choix exclusif, mais de l’articulation entre les composants.
Le lakehouse : pourquoi on en parle autant
Si le lakehouse suscite autant d’intérêt, ce n’est pas par effet de mode. Il répond à une problématique très concrète : comment concilier l’agilité du data lake avec les exigences de la BI structurée.
Le papier fondateur présenté à CIDR a largement contribué à populariser cette approche. Il met en lumière l’intérêt des formats ouverts et des moteurs analytiques modernes pour unifier la business intelligence et l’analytique avancée, sans multiplier les silos techniques.
Le lakehouse ne cherche donc pas à remplacer l’existant, mais à réduire la fracture historique entre exploration et décision. Cette unification n’est toutefois possible que si le lakehouse s’inscrit dans une logique de produits de données clairement gouvernés, avec des règles explicites de qualité, d’accès et de responsabilité.
Formats ouverts : un détail qui évite bien des regrets
Cette promesse d’unification repose sur un élément souvent discret, mais fondamental : le choix des formats de données. Dans une architecture BI moderne, les formats ouverts constituent un véritable garde-fou contre le verrouillage technologique.
Des formats comme Apache Parquet se sont imposés comme des standards de fait. Ils offrent un stockage efficace, optimisé pour la lecture analytique, tout en restant largement compatibles avec les principaux moteurs de calcul. C’est un choix pragmatique pour préserver l’évolutivité de la plateforme sans sacrifier la performance.
Avant même de parler d’outils ou de moteurs, ce sont donc ces choix structurants qui conditionnent la liberté d’évolution à moyen et long terme.
L’enjeu réel : gouverner l’agilité
Mais l’agilité, sans cadre, se retourne vite contre l’organisation. Un data lake mal gouverné devient rapidement un marécage. Et le lakehouse n’échappe pas à cette règle.
Sans règles claires de gestion, de qualité et de sécurité des données, l’architecture BI perd en crédibilité, quelle que soit la sophistication technologique. La bonne approche consiste à définir des responsabilités explicites, des conventions de nommage partagées, des contrôles automatisés et un catalogue de données vivant.
L’objectif est simple en apparence : aller vite, sans tomber dans le chaos. C’est à cette condition que le data lake et le lakehouse deviennent de véritables piliers d’une architecture BI moderne orientée décision.
Plateforme de décision : l’architecture BI qui active vraiment l’analytique et l’IA
À ce stade de la modernisation de la BI, une question devient centrale. Une fois les données collectées, structurées et gouvernées, comment s’assurer qu’elles produisent réellement de la décision ? C’est précisément le rôle de la plateforme de décision, pensée non comme un outil supplémentaire, mais comme l’aboutissement naturel d’une architecture BI moderne.
Les composants minimum viable d’une plateforme
Une plateforme de décision va bien au-delà du simple stockage. Elle repose sur un ensemble cohérent de briques : ingestion des données en batch et en temps réel, orchestration, transformations, couche sémantique, outils de BI et mécanismes d’observabilité.
Elle doit également supporter l’analytique avancée et l’IA, depuis la gestion des features jusqu’à l’entraînement, au déploiement et au monitoring des modèles. Sans cette industrialisation, l’IA reste cantonnée à des POC successifs, sans véritable passage à l’échelle. Une architecture BI moderne vise précisément à transformer l’expérimentation en capacité opérationnelle durable.
BI, sémantique et self service : le trio gagnant
Des tableaux de bord bien conçus ne suffisent pas si les métriques n’ont pas la même signification d’une équipe à l’autre. C’est ici que la couche sémantique devient centrale.
Les modèles sémantiques permettent de stabiliser la définition des indicateurs, de documenter leur sens et de les rendre partageables. Ils constituent un socle commun sur lequel s’appuient les usages de BI et de self service analytics. Des outils comme Power BI exploitent justement ces modèles sémantiques pour proposer une base cohérente, prête pour le reporting et la visualisation.
Cette approche réduit les ambiguïtés, accélère l’adoption et limite les débats interminables autour des chiffres.
Coûts, performance et le piège du tout temps réel
Le temps réel est souvent perçu comme un objectif absolu. Pourtant, tout traiter en temps réel est l’un des moyens les plus rapides de déséquilibrer les coûts cloud sans réel gain décisionnel.
Dans une architecture BI moderne, les usages doivent être distingués. La décision opérationnelle immédiate, le pilotage quotidien et l’analyse stratégique n’impliquent pas le même niveau de fraîcheur des données. C’est cette hiérarchisation qui permet d’optimiser réellement l’architecture : le bon stockage, le bon moteur de calcul et le bon pipeline de données pour chaque besoin.
Un point souvent sous estimé : l’adoption par les métiers
Au final, une plateforme de décision ne vaut que par son usage. Si les métiers ne s’en emparent pas, l’architecture reste théorique.
L’adoption repose sur du self service BI accessible, des indicateurs co-construits et une capacité à transformer des analyses complexes en récits clairs et actionnables. Chez Eulidia, cet enjeu est central : optimiser les modèles, améliorer la qualité des données et faire en sorte que l’analytique parle réellement au management. Parce que c’est à ce moment-là que la décision se déclenche.
Modernisation de la BI : gouvernance, conformité et sécurité des données, sans freiner l’innovation
À mesure que la BI gagne en puissance et que l’IA s’intègre dans les usages, la question n’est plus de savoir s’il faut gouverner, sécuriser et encadrer. La vraie question est plutôt la suivante : comment le faire sans bloquer l’innovation ? Une architecture BI moderne apporte justement des réponses lorsqu’elle intègre ces sujets dès la conception.
Gouvernance : pas un fardeau, un accélérateur
La gouvernance des données est souvent perçue comme une contrainte. Sur le terrain, c’est l’inverse. Lorsqu’elle est bien pensée, elle évite les reworks, les débats interminables et les KPI contradictoires qui ralentissent la prise de décision.
Les organisations qui réussissent posent un cadre clair dès le départ : définitions partagées des données, ownership explicite, gestion fine des accès et qualité automatisée. Ce cadre ne fige pas les usages. Il les rend au contraire plus fiables et plus rapides à déployer.
Sur ces sujets, des organismes de référence comme le NIST travaillent également sur des profils dédiés à la data governance et au data management. Des ressources utiles pour structurer une approche cohérente à l’échelle de l’entreprise.
RGPD : la base, surtout quand l’IA s’invite
Dès lors que l’on centralise des données personnelles, le RGPD n’est pas optionnel. Il encadre la finalité des traitements, la minimisation des données, leur sécurité, leur durée de conservation et les droits des personnes concernées.
Une architecture BI moderne doit donc intégrer la conformité dès la conception. Classification des données, masquage, chiffrement et traçabilité ne sont pas des ajouts tardifs, mais des briques structurantes de la plateforme de décision.
Le texte officiel du RGPD est accessible sur EUR Lex, et reste une référence incontournable pour aligner architecture, usages et conformité.
IA : penser aussi AI Act, pas seulement modèle
Lorsque l’IA est industrialisée au sein d’une plateforme de décision, un autre cadre réglementaire entre en jeu : l’AI Act européen. Même sans être juriste, un décideur doit comprendre où se situent les risques et les obligations.
Il ne s’agit pas uniquement de performance des modèles, mais aussi d’usage, de conformité, de documentation, de supervision et d’impact. Ces dimensions conditionnent la capacité à déployer l’IA durablement, sans exposition excessive aux risques réglementaires.
Là encore, le règlement est publié sur EUR Lex, et constitue une lecture clé pour toute organisation qui souhaite passer de l’expérimentation à l’industrialisation.
Sécurité : un langage commun avec l’IT et le risk
Dans les grandes organisations, la sécurité des données ne peut pas être traitée en silo. Elle doit s’inscrire dans un langage commun avec les équipes IT, sécurité et risk management.
Des normes comme ISO IEC 27001 restent des références solides pour structurer un système de management de la sécurité de l’information. Elles offrent un cadre reconnu, compréhensible par l’ensemble des parties prenantes.
Côté cloud, des guides publiés par des agences publiques comme l’ENISA apportent également un éclairage précieux pour cadrer les risques, poser les bonnes questions aux fournisseurs et sécuriser les architectures distribuées.
Finalement, la gouvernance, la conformité et la sécurité ne sont pas des freins. Bien intégrées, elles deviennent des facteurs de confiance, indispensables pour faire de la modernisation de la BI un levier durable de performance et de décision.
BI architecture framework : équipes, processus et pilotage de la valeur
Une architecture BI moderne ne repose pas uniquement sur des choix technologiques. Elle tient tout autant à la manière dont les équipes travaillent ensemble, dont les priorités sont arbitrées et dont la valeur est pilotée dans le temps. C’est là que le BI architecture framework prend tout son sens : comme un cadre d’alignement, pas comme une recette figée.
Le bon modèle d’équipe, sans dogme
Une architecture BI moderne ne progresse jamais avec une seule équipe « data magique ». Sur le terrain, on observe plutôt un équilibre entre plusieurs rôles complémentaires : data engineers pour les flux et l’ingestion, analytics engineers pour la couche analytique, data product owners pour le lien avec les métiers, et un socle de gouvernance transverse.
L’enjeu n’est pas le titre affiché sur LinkedIn, mais la clarté des responsabilités et la qualité de la coordination. Quand chacun sait ce qu’il porte et pourquoi, l’architecture gagne en fluidité et en crédibilité.
Aligner la feuille de route sur la stratégie
C’est souvent ici que les programmes data se dispersent. Trop d’outils, trop d’initiatives parallèles, et pas assez de priorités clairement assumées.
Une démarche de data stratégie permet de partir des cas d’usage métiers, de les prioriser et de définir une trajectoire réaliste. On ne modernise pas la BI pour cocher des cases technologiques, mais pour améliorer la performance, la prise de décision et l’efficacité opérationnelle. Le reste n’est que bruit.
Transformer sans casser : rythme, gouvernance et conduite du changement
La transformation data se joue autant dans l’organisation que dans la technique. Il faut savoir livrer vite, apprendre, puis industrialiser. Mais cette agilité n’est possible qu’avec un cadre clair.
Conventions partagées, pipelines en CI CD, tests de qualité automatisés, observabilité des flux : ces pratiques structurent la modernisation sans la ralentir. Sans cette discipline, le temps réel et l’IA deviennent rapidement ingérables, même avec les meilleures technologies.
Une liste simple pour démarrer, sans se raconter d’histoires
Lorsqu’il s’agit de passer à l’action, une séquence pragmatique vaut souvent mieux qu’un grand plan théorique. Voici une approche qui fonctionne fréquemment sur le terrain :
- Cartographier les sources, les flux et les irritants côté métiers
- Identifier trois cas d’usage à fort ROI, clairement mesurables
- Définir une couche sémantique et des KPI officiels
- Choisir un socle adapté, entre entrepôt de données cloud, data lake ou architecture hybride, avec ses garde fous
- Mettre en place une démarche DataOps : tests, monitoring, gestion des accès et des coûts
- Livrer, mesurer l’usage, puis itérer pour délivrer de la valeur
Cette progression évite les effets tunnel et permet d’ancrer rapidement la BI dans les usages réels.
Le rôle du cloud : performance, coûts et positionnement agnostique
Le cloud s’impose souvent comme le meilleur levier pour passer à l’échelle. Mais cette flexibilité a un prix. Sans pilotage, les coûts peuvent dériver aussi vite que les usages.
FinOps, quotas, optimisation du calcul et choix d’architectures sobres deviennent alors indispensables. Chez Eulidia, cette approche se traduit par une vision cloud centric, avec des données unifiées, des performances maîtrisées et une attention constante aux coûts. Le tout en restant agnostique vis-à-vis des technologies cloud, afin de préserver la liberté de choix et d’évolution.
Finalement, un BI architecture framework efficace ne cherche pas la perfection théorique. Il crée les conditions pour aligner équipes, processus et technologie autour d’un objectif commun : produire de la valeur, durablement.
Conclusion
Une architecture BI moderne n’est pas une destination finale. C’est une capacité durable, qui permet de centraliser intelligemment, d’optimiser les pipelines et de rendre l’analytique fiable à grande échelle. Pour les grandes organisations qui souhaitent industrialiser l’IA, elle devient même un prérequis. Sans gouvernance, sans sémantique partagée et sans sécurité intégrée, la plateforme de décision reste fragile et difficile à faire évoluer.
La bonne nouvelle est simple. Il n’est pas nécessaire de tout transformer en une seule fois. La modernisation de la BI peut se faire par étapes, en partant des cas d’usage à forte valeur, en sécurisant progressivement les données et en gardant un cap clairement orienté business.
Lorsque la plateforme commence à tenir, les effets sont visibles. Les décisions deviennent plus rapides, plus lisibles et moins sujettes aux débats stériles. Et c’est souvent à ce moment-là que l’architecture BI cesse d’être perçue comme un sujet technique, pour devenir un véritable levier de pilotage et de performance.
FAQs
Qu’est ce qu’une architecture BI moderne et pourquoi l’adopter
Une architecture BI moderne combine architecture data, cloud, data lake et lakehouse ainsi que des outils de business intelligence pour exploiter l’ensemble des données de l’entreprise, structurées comme non structurées. Elle vise à fiabiliser la donnée, accélérer l’analyse, y compris en quasi temps réel, et faciliter la prise de décision grâce à des tableaux de bord cohérents et au self service BI.
Comment choisir entre data warehouse, data lake et lakehouse
Le choix dépend principalement des types de données, des volumes et des cas d’usage.
Un data warehouse est adapté aux données structurées, au reporting réglementaire et aux analyses historiques.
Un data lake permet de stocker des données brutes à grande échelle, utiles pour l’exploration et l’IA.
Le lakehouse combine les avantages des deux en proposant des capacités analytiques avancées avec une gouvernance des données renforcée.
Quels sont les composants essentiels d’une architecture data pour la business intelligence
Une business intelligence architecture repose sur plusieurs briques clés : sources de données, pipelines de données ETL ou ELT, stockage analytique comme l’entrepôt de données cloud ou le data lake, moteurs de calcul, outils BI comme Power BI, couche sémantique, gouvernance et sécurité des données. Ensemble, ces composants forment une plateforme de décision cohérente.
Comment structurer les flux et pipelines de données pour optimiser les performances
L’optimisation passe par une séparation claire entre ingestion des données brutes, transformations, stockage optimisé et exposition pour les usages analytiques. Combiner des traitements batch pour les volumes importants et du temps réel pour les usages opérationnels permet d’équilibrer performance, coûts et latence dans une architecture BI moderne.
Quel stockage privilégier dans le cloud pour une architecture BI évolutive
Le cloud offre plusieurs options complémentaires. Le data lake permet un stockage économique des données brutes. Les data warehouses managés offrent des performances élevées pour l’analytique. Les architectures lakehouse constituent un compromis intéressant. Le choix dépend des coûts, des besoins en fraîcheur des données et de la compatibilité avec l’écosystème technologique existant.
Comment assurer la qualité des données et la gouvernance dans une architecture BI
La qualité repose sur des contrôles automatisés, des règles de nettoyage, un data lineage clair et une gouvernance centralisée. La définition partagée des indicateurs et l’implication conjointe des équipes IT, data et métiers sont essentielles pour garantir la fiabilité et la conformité des données dans la durée.
Peut on intégrer l’IA dans une architecture BI pour améliorer l’analytique
Oui. L’IA et le machine learning peuvent être intégrés aux pipelines de données pour enrichir l’analyse, détecter des tendances et automatiser certaines décisions. Les data lakes et les bases analytiques servent de socle à l’entraînement des modèles, dont les résultats peuvent ensuite alimenter les tableaux de bord et la prise de décision.
Comment sécuriser les données et maîtriser les coûts de stockage
La sécurité repose sur le chiffrement, la gestion fine des accès, la traçabilité et les audits. Pour maîtriser les coûts, il est essentiel de distinguer données actives et données archivées, d’optimiser les formats de stockage et de définir des politiques de rétention adaptées. Une architecture BI moderne intègre ces arbitrages dès la conception.
Quels sont les principaux défis d’une architecture BI et comment les surmonter
Les défis concernent l’intégration des sources, la montée en volume, la qualité des données, les silos et la gouvernance. Les surmonter passe par une stratégie claire, un BI architecture framework adapté, des outils modernes et une collaboration étroite entre IT et métiers. Dans un contexte d’évolution rapide des usages et des technologies, une veille continue reste indispensable.



.svg)
