
Sécuriser une IA ne consiste pas à “protéger un modèle”.
C’est sécuriser tout ce qui permet à ce modèle d’exister, d’apprendre et d’agir.
Concrètement, cela inclut les données, le code, les pipelines, les accès, les logs et les usages métier, du cadrage jusqu’à l’exploitation. Et c’est souvent là que tout se joue : la sécurité du cycle de vie de l’IA repose moins sur une promesse de “modèle robuste” que sur une multitude de détails opérationnels, droits d’accès, traçabilité, tests, séparation des environnements.
Dans nos missions, un constat revient systématiquement : les entreprises qui avancent vite sur l’IA sans créer de dette de risque ont un point commun. Elles ne traitent pas la sécurité comme une contrainte, mais comme une discipline intégrée dès le départ, au service de l’industrialisation des usages IA.
Alors, que recouvre réellement cette notion de sécurité “de bout en bout” ?
Comprendre la sécurité de l’IA et l’enjeu du cycle de vie
La sécurité de l’IA n’est pas un audit en fin de projet.
C’est une approche continue, qui traverse l’ensemble du cycle de vie : choix des données, gestion des environnements, dépendances techniques, modèles, interfaces applicatives… jusqu’aux usages réels côté métier.
Et c’est précisément là que le sujet devient critique.
Dans les grandes organisations, le risque vient rarement d’un seul point faible. Il s’accumule, circule entre les briques, puis se révèle souvent au pire moment, en production.
Définition : qu’est-ce que la sécurité pour les systèmes d’IA ?
Pour un système d’IA, la sécurité peut se résumer à trois objectifs opérationnels : empêcher les accès non autorisés, éviter les fuites de données, de secrets ou de logique métier, et garantir un service fiable sous contrainte.
- empêcher les accès non autorisés
- éviter les fuites (données, secrets, logique métier)
- garantir un service fiable, même sous contrainte
Sur le papier, rien de nouveau.
Mais en pratique, l’IA change la donne.
Elle introduit de nouvelles surfaces d’attaque : données d’entraînement, prompts, connecteurs, chaînes d’outils, mais aussi des sorties capables de déclencher des actions (agents IA, automatisations, exécution de fonctions).
Autrement dit : le système ne se contente plus de répondre, il peut agir.
Pourquoi la sécurité IA est différente : données, modèles, prompts, chaîne d’outils
Dans un système d’information classique, on contrôle principalement les accès et les flux entrants.
Avec l’IA, il faut aller plus loin :
- contrôler ce qui est appris (les données)
- contrôler ce qui est généré (les outputs)
- contrôler ce qui est exécuté (les actions)
Prenons un cas concret : une application qui appelle un LLM, enrichit la réponse via un RAG, puis déclenche une action via API.
Sur le papier, c’est un use case standard.
En réalité, c’est une chaîne complexe où chaque étape peut introduire un risque.
Et c’est précisément ce que recherchent les attaquants :
les zones grises entre “texte”, “connaissance” et “commande”.
Pourquoi sécuriser tout le cycle de vie est essentiel?
Plus une organisation industrialise ses cas d’usage IA, plus elle mutualise :
- datasets partagés
- features réutilisées
- modèles ré-entraînés
- prompts copiés
- composants communs
C’est un levier de performance évident.
Mais c’est aussi un multiplicateur de risque.
Une permission trop large, un connecteur mal filtré, un log trop verbeux… et le problème ne reste jamais local. Il se propage.
L’erreur devient scalable.
Une mauvaise configuration locale peut alors produire un effet systémique à l’échelle de plusieurs cas d’usage.
Il ne s’agit plus seulement de “sécuriser un projet”, mais de gérer un système de risques distribué, avec :
- une vision consolidée
- des contrôles répétés
- une gouvernance claire
Et surtout, une question simple à chaque étape :Si ce composant est compromis, quel est l’impact réel ?
Risques et menaces : ce qu’il faut vraiment identifier
Il est toujours possible de multiplier les scénarios de risque. Mais pour un décideur, l’enjeu n’est pas l’exhaustivité. Il est de savoir où concentrer son attention.
Trois critères permettent de prioriser efficacement : ce qui dégrade la confiance, ce qui génère un impact financier significatif, et ce qui expose à un risque de non conformité ou d’audit.
Dans les systèmes d’intelligence artificielle, les menaces les plus fréquentes se concentrent autour de trois dimensions structurantes : la donnée, les accès, et l’agentivité, c'est-à -dire la capacité du système à déclencher des actions. C’est leur combinaison qui crée des situations de risque nouvelles, souvent sous estimées.
Principales vulnérabilités IA à connaître
Une lecture structurée des risques permet de les regrouper en cinq grandes familles : données, entraînement, inférence, supply chain et exposition applicative.
Dans la pratique, les vulnérabilités ne se situent pas uniquement dans des architectures complexes. Elles apparaissent fréquemment dans des éléments opérationnels du quotidien :
- variables d’environnement exposées
- clés API insuffisamment protégées
- notebooks partagés sans contrôle strict
- buckets de stockage mal segmentés
- duplication de jeux de données dans des environnements de test
À cela s’ajoute un biais fréquent côté produit : l’illusion de contrôle. L’interface applicative donne le sentiment d’un cadre maîtrisé, mais le comportement du modèle reste largement ouvert.
Ce décalage entre perception et réalité constitue un point de fragilité important, notamment dans des environnements où les utilisateurs peuvent influencer les entrées.
Les risques majeurs en production
En environnement de production, certains scénarios apparaissent de manière récurrente dans les analyses de risque :
- exfiltration de données via des connecteurs tels que CRM, SharePoint ou data warehouse, ou via des logs trop détaillés
- empoisonnement des données d’entraînement dans des pipelines insuffisamment contrôlés
- extraction de logique métier par usage détourné d’API ou de mécanismes d’observabilité
- contournement des politiques de sécurité via des attaques par injection ou des techniques de jailbreak
- déni de service lié à des requêtes coûteuses ou à une mauvaise gestion du contexte
Ces risques sont largement documentés dans les référentiels de l’industrie, notamment l’OWASP Top 10 for LLM, et doivent être considérés comme des scénarios de base dans toute analyse sérieuse.
Qui attaque, et pourquoi ?
L’image d’un attaquant externe très sophistiqué ne correspond pas toujours à la réalité des environnements d’entreprise.
Les profils impliqués sont variés : collaborateurs internes, prestataires, partenaires ou acteurs opportunistes. Dans certains cas, l’intention n’est même pas initialement malveillante, mais le résultat peut néanmoins créer une exposition significative.
Les motivations restent pragmatiques : accès à des données sensibles, compréhension de logiques métier, avantage concurrentiel ou opportunité financière.
Dans le contexte de l’IA générative, la surface d’expérimentation offerte à un attaquant est particulièrement large. Il n’est plus nécessaire d’exploiter une vulnérabilité technique complexe. L’attaque peut passer par une exploration progressive des entrées, jusqu’à identifier un comportement exploitable.
Comment cartographier les menaces : le threat modeling IA
Le threat modeling appliqué à l’IA repose sur les mêmes principes que dans les systèmes applicatifs traditionnels, mais avec deux dimensions supplémentaires : la donnée et les comportements émergents.
La démarche s’articule autour de trois étapes :
- identifier les actifs critiques
- cartographier les vecteurs d’attaque
- évaluer les impacts métier
La difficulté principale tient à la nature même des systèmes d’IA. Certains comportements ne sont pas explicitement programmés, mais générés, ce qui rend leur anticipation plus complexe.
Pour structurer cette analyse, de nombreuses équipes s’appuient sur des référentiels comme MITRE ATLAS, qui permettent de relier des techniques d’attaque à des stratégies de mitigation.
L’objectif n’est pas de couvrir tous les scénarios possibles, mais de disposer d’un cadre robuste pour prioriser les risques réellement critiques et orienter les décisions de sécurité.
Identifier et tester : détecter les attaques et mesurer la robustesse
Ce qui rassure un COMEX, ce n’est pas le fait d’avoir déployé de l’IA.
C’est la capacité à dire, de manière factuelle : nous savons détecter une dérive, et nous savons y répondre.
Autrement dit, la sécurité repose ici sur trois piliers indissociables : tester, observer, démontrer.
Dans la pratique, un écueil revient souvent. Lorsque les systèmes d’IA ne sont pas testés en continu, ils sont pilotés à l’intuition. Tant que tout fonctionne, le risque reste invisible. Mais dès qu’un comportement inattendu apparaît, l’absence de cadre devient un coût immédiat, souvent élevé, et difficile à rattraper.
Comment détecter les tentatives d’attaque contre les systèmes d’IA ?
Détecter une tentative d’attaque ne consiste pas uniquement à bloquer des requêtes. Il s’agit d’observer des dynamiques d’usage et d’identifier des signaux faibles.
Certains patterns reviennent de manière récurrente : une augmentation anormale du volume de tokens, des séquences de requêtes quasi identiques, des tentatives répétées d’accès à des informations sensibles, ou encore une exploration progressive des limites du système. Pris isolément, ces signaux peuvent sembler anodins. Mais combinés, ils révèlent souvent une stratégie.
C’est pourquoi la détection doit couvrir l’ensemble de la chaîne. Les entrées, bien sûr, mais aussi les sorties générées, les appels d’outils et les accès aux sources de données. Une anomalie n’apparaît pas toujours là où on l’attend.
Dans ce contexte, la télémétrie devient un élément structurant. Sans logs exploitables, corrélables et suffisamment détaillés, il devient extrêmement difficile de distinguer un utilisateur curieux d’un comportement malveillant organisé.
Tests de sécurité IA : ce qui fonctionne réellement en entreprise
Les dispositifs de test efficaces reposent rarement sur une seule approche. Ils combinent des scénarios réalistes, des tests de robustesse et des explorations systématiques des comportements du modèle.
Le red teaming permet de se rapprocher de situations réelles, en reproduisant des usages adverses crédibles. Les tests adversariaux mettent en évidence la sensibilité du modèle à des variations d’entrées parfois minimes. Quant au fuzzing de prompts, il permet d’explorer à grande échelle des combinaisons que les équipes n’auraient pas envisagées manuellement.
Mais un point reste souvent sous-estimé : le modèle n’est qu’une partie du système. Les connecteurs, les mécanismes de filtrage et la couche applicative jouent un rôle tout aussi critique. Un modèle bien sécurisé peut rester contournable si son environnement ne l’est pas.
Cela impose un changement de perspective. Il ne suffit plus de tester ce que le système reçoit. Il faut également tester ce qu’il produit, en particulier lorsque ces sorties peuvent déclencher des actions.
Mesures et indicateurs : piloter sans se perdre
L’enjeu n’est pas d’accumuler des métriques, mais de construire un cadre de pilotage lisible et actionnable.
Dans la plupart des organisations, quelques indicateurs bien choisis suffisent à donner une vision claire du niveau de contrôle réel. Encore faut-il savoir à quoi correspondent concrètement ces signaux dans le système.
Voici une grille de lecture simple, souvent utilisée en pratique :
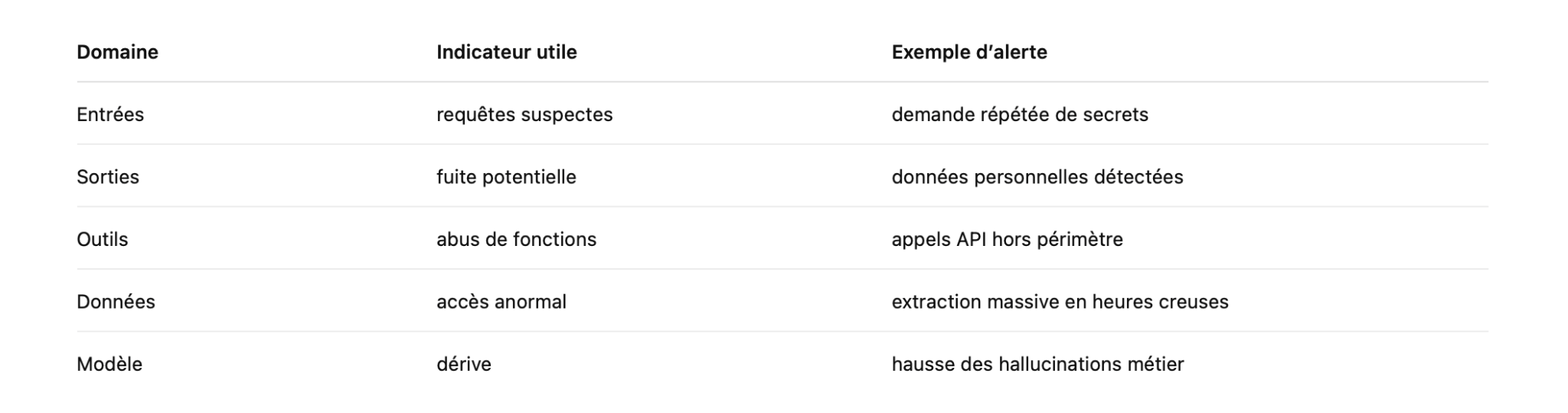
Ces indicateurs prennent toute leur valeur lorsqu’ils sont reliés à des cas d’usage précis. Sans critères d’acceptation définis, les équipes se retrouvent rapidement à arbitrer sur des métriques abstraites, sans lien direct avec l’impact métier.
Un autre équilibre doit être pris en compte. Une sécurité trop contraignante dégrade l’expérience utilisateur. Et dans ce cas, les contournements apparaissent presque toujours, volontairement ou non.
Gestion des vulnérabilités : triage et amélioration continue
La gestion des vulnérabilités ne peut pas être traitée comme une étape ponctuelle. Elle s’inscrit dans une logique d’apprentissage continu.
Chaque incident devient une source d’information. Encore faut-il être capable de le qualifier, de le prioriser et d’en tirer des actions concrètes. Cela implique de structurer les événements, d’évaluer leur impact métier, puis d’ajuster en continu les mécanismes existants : prompts, règles, droits d’accès et scénarios de test.
Ce processus fonctionne en boucle, y compris lorsque le système semble stable.
C’est précisément cette capacité à maintenir un niveau de vigilance constant et à améliorer le dispositif sans attendre une défaillance majeure qui distingue les organisations réellement matures en matière de sécurité de l’IA.
Sécuriser la phase de développement : Security by Design et MLOps sécurisé
Une erreur fréquente consiste à traiter l’IA comme un POC permanent.
Ce fonctionnement peut convenir en phase d’exploration, mais il devient rapidement un frein dès que l’on vise un passage à l’échelle.
Les grandes organisations attendent autre chose. Elles cherchent de la fiabilité, de l’observabilité et une trajectoire claire d’industrialisation. La question n’est donc plus « peut-on prédire », mais « peut-on déployer, surveiller, corriger et expliquer ».
C’est précisément à ce stade que la sécurité doit être intégrée, non comme une couche supplémentaire, mais comme un principe structurant du développement.
Gouvernance et gestion des risques dès la conception
La sécurisation commence dès le cadrage. Il ne s’agit pas uniquement de définir un cas d’usage, mais de comprendre ses implications : quels impacts métier, quelles données mobilisées, quels rôles impliqués.
Une question est souvent négligée, alors qu’elle est structurante : que ne doit jamais faire le système ?
Définir cette ligne rouge permet d’orienter les choix techniques et de limiter les dérives dès le départ.
À partir de là, la formalisation devient essentielle. Registre des cas d’usage, classification des systèmes, exigences de conformité. Ces éléments ne sont pas bureaucratiques, ils permettent de créer un cadre cohérent.
Des référentiels comme le NIST AI RMF offrent une base solide pour structurer cette démarche, sans ralentir l’innovation.
Mesures de sécurité pendant le développement
En phase de développement, les risques ne viennent pas de choix complexes, mais de pratiques trop permissives.
On retrouve systématiquement les mêmes situations : notebooks partagés sans contrôle, secrets copiés entre environnements, confusion entre dev, test et production. Ce sont ces raccourcis qui créent les vulnérabilités les plus exploitables.
Les fondamentaux restent donc déterminants. Une gestion stricte des identités et des accès, l’utilisation d’un gestionnaire de secrets, des revues de code systématiques, et des pipelines CI/CD capables de détecter des dépendances ou des configurations à risque.
Côté MLOps, un changement de posture s’impose. Un modèle ou un dataset ne doit plus être traité comme un simple fichier. Chaque artefact devient un actif critique, qui doit être versionné, signé et traçable.
C’est à ce moment que l’on bascule d’une logique expérimentale à une logique industrielle.
Sécuriser données et modèles : provenance, intégrité et supply chain
La question de la provenance devient centrale dès lors que l’on manipule des modèles d’IA.
D’où viennent les données ? Sous quelles licences sont-elles utilisées ? Quelles transformations ont été appliquées ? Quelles validations ont été réalisées ?
Sans réponses claires à ces questions, il devient difficile de garantir la fiabilité du système, et encore plus de répondre à un audit.
La gestion de l’intégrité est tout aussi critique. Signatures, contrôles, traçabilité des versions. À l’inverse, les téléchargements manuels ou les manipulations non contrôlées introduisent des risques difficiles à détecter.
La supply chain constitue aujourd’hui un vecteur d’attaque majeur : dépendances logicielles, images de conteneurs, modèles tiers, librairies open source ou composants de serving peuvent tous introduire une exposition critique. Notamment dans l’OWASP Top 10 for LLM. Elle doit être traitée comme telle, avec des contrôles explicites.
Enfin, la discipline documentaire n’est pas un détail. Elle conditionne la capacité à démontrer la conformité et à gérer un audit sans improvisation.
Bonnes pratiques spécifiques à l’IA générative
Avec l’IA générative, la sécurité ne dépend pas uniquement du modèle, mais de l’architecture dans son ensemble.
Un système basé sur RAG peut mieux borner la connaissance mobilisée et réduire certaines hallucinations factuelles, à condition de contrôler les sources, le retrieval et les droits d’accès.
Mais il introduit aussi des points d’accès supplémentaires, qu’il faut encadrer.
De la même manière, un agent capable d’utiliser des outils augmente fortement la valeur métier. Mais il élargit également la surface d’attaque.
L’enjeu devient alors un arbitrage. Filtrer les sources, contrôler les accès, limiter les outils disponibles et isoler l’exécution lorsque c’est nécessaire.
Un principe reste fondamental : un système ne doit pas exécuter une action simplement parce qu’un modèle l’a suggérée. Cette intention doit être validée, contrôlée et contextualisée.
C’est à ce niveau que se joue la différence entre un prototype fonctionnel et un système réellement maîtrisé.
Protéger les données tout au long du cycle de vie
Dans de nombreuses organisations, la donnée constitue l’actif le plus critique.
C’est elle qui crée la valeur, mais c’est aussi elle qui concentre le risque.
Dans ce contexte, la sécurité des données devient le pilier central de toute stratégie de sécurité de l’IA. Si ce socle est fragile, le reste du dispositif perd en efficacité. Et contrairement à une idée répandue, protéger les données ne consiste pas uniquement à chiffrer et à espérer que cela suffise.
La question est plus large. Elle touche à la manière dont les données sont sélectionnées, exposées, utilisées et gouvernées dans le système.
Sécurité des données : chiffrement, minimisation et contrôle des accès
Les principes fondamentaux restent connus, mais leur mise en œuvre dans un contexte IA demande de la rigueur.
Il s’agit d’abord de comprendre ce que l’on manipule. Classifier les données, identifier leur sensibilité, puis adapter leur exposition en conséquence. La minimisation joue ici un rôle clé. Plus un système accède à des données larges, plus il augmente mécaniquement sa surface de risque.
La gestion des accès est l’autre levier structurant. Qui peut voir quoi, dans quel contexte, avec quel niveau de traçabilité. Cela implique une séparation claire des environnements, ainsi qu’une journalisation exploitable des accès.
En pratique, cette approche repose sur un équilibre entre gouvernance, outils de type DLP et design applicatif. Un point est souvent sous-estimé. Si les données ne sont pas bien structurées, interopérables et gouvernées, l’IA ne corrige pas ces faiblesses. Elle les amplifie et les rend visibles à grande échelle.
Risques liés aux données : des fuites souvent indirectes
Les incidents liés aux données ne prennent pas toujours la forme d’une attaque directe.
Dans certains cas, un modèle peut mémoriser ou restituer des fragments sensibles issus des données d’entraînement, en particulier si les garde-fous ou les pratiques de préparation des données sont insuffisants.
Les logs peuvent capturer des informations critiques sans que cela soit anticipé. Un connecteur trop permissif peut exposer des documents hors du périmètre initialement prévu.
Mais les risques les plus fréquents restent souvent opérationnels.
Des équipes copient des extraits de données dans des tickets, des tableurs ou des prompts, dans une logique de test rapide. Ces pratiques, anodines en apparence, créent des points de fuite difficiles à contrôler.
C’est ainsi que de nombreux incidents apparaissent, sans qu’aucune attaque sophistiquée ne soit nécessaire.
Règles pratiques pour réduire les risques
Dans ce contexte, certaines pratiques ont un effet disproportionné sur la réduction du risque.
La première consiste à classifier systématiquement les données utilisées dans les systèmes d’IA. Sans cette étape, il devient difficile d’adapter les contrôles.
La seconde est de restreindre ce que le modèle peut effectivement voir et manipuler. L’accès par défaut ne doit jamais être large.
La troisième repose sur la traçabilité. Savoir qui a accédé à quoi, dans quel contexte, et pour quel usage.
À cela s’ajoute une règle souvent négligée mais déterminante. Les données de production ne devraient pas être exposées aux usages expérimentaux sans cadre strict, mécanismes de masquage ou environnement dédié. Les environnements hybrides, où POC et données réelles cohabitent, sont une source fréquente d’incidents.
C’est précisément dans ces zones de compromis que la sécurité se dégrade le plus rapidement.
Sécuriser le déploiement et l’exploitation en production
La mise en production est toujours un moment de bascule.
C’est là que les hypothèses rencontrent la réalité : trafic réel, cas d’usage imprévus, utilisateurs pressés et intégrations multiples.
Dans ce contexte, une règle s’impose. Une sécurité qui n’est pas observable est une sécurité qui n’existe pas
Concrètement, cela signifie que les mécanismes doivent être visibles dans les logs, mesurables via des indicateurs opérationnels, et activables rapidement en cas d’incident. Droits d’accès, segmentation réseau, quotas, filtrage des entrées et des sorties, procédures d’incident. Rien ne peut rester implicite.
Déploiement IA : plateformes, contrôle d’accès et segmentation
Que le déploiement se fasse sur le cloud, en on prem ou dans un environnement hybride, les principes restent les mêmes.
Le moindre privilège constitue la base. Chaque service, chaque application, chaque composant d’IA doit disposer d’une identité propre, avec des permissions strictement limitées à son périmètre. Les clés doivent être rotées régulièrement et les accès réévalués.
La segmentation joue ici un rôle structurant. Séparer les environnements, isoler les flux, limiter les communications entre composants. Ce sont ces mécanismes qui empêchent une faille locale de se propager.
Lorsque des fournisseurs externes sont impliqués, le niveau d’exigence ne doit pas baisser. Les engagements doivent être audités, les logs accessibles et exploitables, et les options de résidence des données clairement maîtrisées.
Surveillance continue : logs, abus, dérive et alerting
Une fois en production, la sécurité repose sur la capacité à observer les usages en continu.
Cela implique d’instrumenter les pipelines, de tracer les appels et de corréler les événements avec les outils de supervision existants, notamment les SIEM et SOAR. Mais au-delà des outils, c’est la nature des signaux qui compte.
Surveiller uniquement les entrées ne suffit pas. Les sorties doivent être analysées avec le même niveau d’attention, en particulier lorsque le système peut produire des actions ou exposer des informations sensibles.
Dans de nombreux cas, l’analyse de patterns d’usage s’avère plus efficace que des scores de risque opaques. Des séquences de requêtes, des comportements répétitifs ou des usages atypiques donnent souvent des signaux plus exploitables.
Protéger utilisateurs et applications
La couche applicative reste la première ligne de défense.
C’est à ce niveau que s’opèrent le filtrage des entrées, la validation des sorties et le contrôle des interactions avec les outils. Le rate limiting permet de contenir les abus, tandis que la gestion fine des droits détermine qui peut accéder à quoi et dans quelles conditions.
Un point est souvent sous-estimé. Ces mécanismes ne doivent pas être traités comme des correctifs, mais comme des composants à part entière du produit. Ils doivent être testés, maintenus et évalués avec le même niveau d’exigence que le reste de l’application.
Réponse aux incidents IA : préparation et retour d’expérience
Aucun système n’est exempt d’incident. La différence se joue dans la capacité à réagir rapidement et de manière structurée.
Cela suppose de définir à l’avance des playbooks adaptés aux scénarios les plus probables : fuite de données, dérive du modèle, abus d’un agent, extraction via API. Un kill switch simple à activer et des mécanismes de rollback maîtrisés permettent de limiter l’impact immédiat.
Mais la gestion ne s’arrête pas à la résolution.
Chaque incident doit donner lieu à une analyse approfondie. Comprendre ce qui a rendu l’incident possible, ce qui a accéléré sa propagation et ce qui doit être renforcé. Sans cette étape, les mêmes failles apparaissent.
C’est dans cette capacité à apprendre et à ajuster en continu que se construit une sécurité réellement robuste en production.
Gouvernance, rôles et montée en compétence
La sécurité de l’IA échoue rarement par manque d’outils.
Elle échoue beaucoup plus souvent par manque de clarté organisationnelle.
Qui décide ? Qui valide ? Qui porte le risque ?
Sans réponses explicites à ces questions, les zones grises s’installent rapidement, en particulier dans des organisations où plusieurs équipes déploient des modèles en parallèle. Et ce flou devient un facteur de risque à part entière.
Une gouvernance efficace ne vise pas à ralentir les initiatives. Elle vise à rendre les décisions visibles, cohérentes et reproductibles.
Rôles et responsabilités
Dans les organisations matures, un schéma se dessine progressivement.
Les équipes Data et Machine Learning portent la responsabilité des solutions
développées. Elles conçoivent, entraînent et intègrent les modèles dans les cas d’usage métier.
Les équipes AppSec interviennent sur la sécurisation de l’architecture et des flux applicatifs.
Les équipes SecOps assurent la surveillance, la détection et la réponse aux incidents en production.
Le DPO encadre l’usage des données, en particulier lorsqu’il s’agit de données personnelles ou sensibles.
Enfin, les fonctions Risk arbitrent les décisions en matière d’exposition et de niveau de sécurité acceptable.
Ce découpage n’a rien de théorique. Il permet d’éviter les angles morts et de s’assurer que chaque décision critique est portée par le bon acteur.
L’enjeu n’est pas d’ajouter des couches de validation, mais de rendre les responsabilités explicites.
Standards et conformité
Le cadre réglementaire et normatif apporte une structure utile, à condition de l’utiliser comme un guide et non comme une contrainte purement formelle.
En Europe, l’AI Act introduit une approche par niveaux de risque. Certains cas d’usage nécessitent des exigences renforcées, notamment en matière de transparence, de documentation et de contrôle.
À l’échelle organisationnelle, la norme ISO/IEC 42001 propose une approche de type management system, fondée sur une logique d’amélioration continue. Elle permet de structurer la gouvernance de l’IA au-delà des projets individuels.
Ces référentiels ne remplacent pas les choix techniques ni les pratiques d’ingénierie. Ils permettent en revanche de démontrer que les systèmes sont maîtrisés, et que les décisions sont encadrées.
Mesurer et piloter
La gouvernance ne peut pas reposer uniquement sur des principes. Elle doit s’appuyer sur des éléments tangibles.
Cela suppose de préparer les preuves en continu. Politiques de sécurité, schémas d’architecture, journaux d’accès, résultats de tests, décisions de validation. Tous ces éléments constituent la base de l’auditabilité.
Mais la documentation seule ne suffit pas. Elle doit être vivante, connectée aux systèmes réels et mise à jour au fil des évolutions.
Les organisations les plus avancées combinent cette documentation avec des contrôles automatisés et une surveillance en temps réel. Cette approche permet non seulement de répondre aux audits, mais aussi de piloter la sécurité de manière proactive.
C’est cette capacité à relier gouvernance, opérationnel et preuve qui fait la différence entre un dispositif théorique et une sécurité réellement maîtrisée.
Sécurité par l’IA : quand l’IA aide à sécuriser l’IA
On oppose souvent intelligence artificielle et sécurité, comme s’il s’agissait de deux dynamiques contradictoires. En réalité, les systèmes d’IA sont déjà utilisés pour renforcer certaines capacités de détection et d’analyse.
Ils permettent notamment de traiter des volumes d’information difficiles à exploiter manuellement. Corrélation de logs, triage d’alertes, identification de signaux faibles. Sur ces dimensions, le gain opérationnel est réel.
Mais cette contribution doit être comprise pour ce qu’elle est. Un levier d’accélération, pas un mécanisme de contrôle autonome.
Détection assistée : menaces et signaux faibles
L’un des apports les plus concrets de l’IA concerne l’analyse des comportements.
En observant des volumes importants de données, un système peut identifier des anomalies difficiles à détecter autrement. Il peut rapprocher des incidents qui semblent isolés, détecter des séquences atypiques ou mettre en évidence des patterns d’usage inhabituels.
Cette capacité est particulièrement utile dans des environnements à grande échelle, où les équipes de sécurité doivent gérer un flux constant d’alertes. L’IA permet alors de prioriser, de regrouper et d’accélérer l’analyse.
Elle peut également être utilisée pour analyser les sorties des systèmes d’IA eux-mêmes. Détection de données sensibles, identification de comportements anormaux ou repérage de tentatives d’abus. Ces usages deviennent rapidement indispensables dès lors que les volumes augmentent.
Limites et précautions
L’utilisation de l’IA pour sécuriser des systèmes d’IA introduit cependant un paradoxe.
Un modèle reste probabiliste. Il peut se tromper, généraliser de manière excessive ou être contourné. Le risque principal n’est pas l’erreur ponctuelle, mais la dépendance. Lorsque la décision est implicitement déléguée à un score, la vigilance diminue.
C’est pourquoi certaines règles doivent rester non négociables. Les cas critiques doivent continuer à s’appuyer sur des mécanismes déterministes. Une supervision humaine reste nécessaire pour valider les décisions les plus sensibles.
Un autre point mérite une attention particulière. Le système de détection ne doit pas disposer du même niveau d’accès que les systèmes qu’il surveille. Dans le cas contraire, il devient lui-même une surface d’attaque.
Finalement, l’IA apporte un avantage clair en matière de détection et d’analyse. Mais elle ne remplace ni la gouvernance, ni les contrôles, ni la responsabilité humaine.
C’est dans cet équilibre que réside son efficacité réelle.
Ce que vous pouvez mettre en place dès maintenant
Face à la complexité des sujets de sécurité de l’IA, la tentation est souvent d’attendre une transformation globale, un “grand soir” qui remettrait tout à plat.
En pratique, ce moment n’arrive jamais.
Les organisations qui progressent adoptent une approche différente. Elles avancent par étapes, en structurant progressivement leur dispositif sur l’ensemble du cycle de vie, sans bloquer les usages existants.
La première étape consiste à clarifier. Cartographier les cas d’usage, identifier les actifs sensibles et comprendre où se situent réellement les points de risque. Sans cette visibilité, les efforts de sécurisation restent dispersés.
Ensuite, il devient essentiel de structurer les fondations. Segmenter les environnements, les données et les identités de service permet de contenir les risques et d’éviter leur propagation. Cette séparation, souvent considérée comme technique, est en réalité un levier majeur de maîtrise.
La mise en place de tests continus constitue une autre étape clé. Il ne s’agit pas seulement de tester le système, mais de définir des critères d’acceptation propres à chaque cas d’usage. C’est ce qui permet de relier la sécurité à des enjeux métier concrets.
Dans le même temps, l’encadrement des connecteurs, des outils et des droits d’exécution devient indispensable. Ce sont eux qui matérialisent la capacité du système à agir, et donc son niveau réel d’exposition.
Une fois ces éléments en place, la priorité se déplace vers la visibilité. Déployer des mécanismes d’observabilité, de détection et des playbooks d’incident permet de passer d’une posture réactive à une posture pilotée.
Enfin, cette trajectoire doit être consolidée par un cadre de gouvernance clair. Formaliser les rôles, structurer les preuves et intégrer les exigences réglementaires, notamment celles de l’AI Act ou de l’ISO 42001, permet de rendre le dispositif durable et auditable.
Ce cheminement ne vise pas la perfection immédiate. Il permet de construire, étape par étape, un système cohérent, capable de supporter une montée en charge réelle de l’IA.
Pour structurer cette transformation, les approches orientées stratégie et transformation permettent de garder un cap clair. L’enjeu reste le même à chaque étape : industrialiser sans perdre le lien avec les usages métier.
Conclusion
Sécuriser l’IA, c’est accepter une réalité structurante.
La valeur ne vient pas du modèle seul. Elle vient de son intégration dans un système plus large. Et c’est précisément là que se concentre le risque.
Déployer de l’IA, ce n’est jamais déployer un composant isolé.
C’est mettre en production un ensemble vivant, composé de données, de pipelines, de modèles, d’applications, d’utilisateurs et de processus opérationnels. Chaque interaction crée de la valeur. Chaque interaction introduit aussi une exposition potentielle.
Dans ce contexte, la sécurité ne peut pas être traitée comme une couche supplémentaire. Elle doit être pensée comme une capacité transverse, intégrée à chaque étape du cycle de vie.
La bonne nouvelle, c’est que cette complexité peut être pilotée, à condition de traiter la sécurité comme une capacité continue et non comme un contrôle ponctuel. Une approche pragmatique, fondée sur des tests continus, une gouvernance explicite, une observabilité réelle et des contrôles d’accès rigoureux, permet d’avancer sans ralentir. Elle permet surtout de réduire les incidents, d’anticiper les dérives et de maintenir un niveau de conformité, même dans des environnements où les systèmes évoluent en permanence.
Mais au-delà de la gestion du risque, un basculement s’opère.
Lorsqu’elle est bien structurée, la sécurité devient un levier. Elle permet d’industrialiser plus vite, de déployer avec plus de confiance et de soutenir des usages à plus forte valeur. Autrement dit, elle cesse d’être une contrainte pour devenir un avantage compétitif.
C’est à ce point que la sécurité de l’IA rejoint la stratégie data et les démarches d’industrialisation. Non comme un sujet séparé, mais comme un élément central de la performance durable.
Sources externes utiles
Pour approfondir et structurer votre approche, certains référentiels font aujourd’hui référence :
- NIST AI Risk Management Framework 1.0
- ISO/IEC 42001:2023 – AI management systems
- OWASP Top 10 for Large Language Model Applications
- MITRE ATLAS
- EU AI Act – EUR-Lex
FAQs about sécurité du cycle de vie de l’IA
Qu’est-ce que la sécurité du cycle de vie de l’IA et pourquoi est-elle cruciale pour les entreprises ?
La sécurité du cycle de vie de l’IA couvre l’ensemble des étapes, de la conception jusqu’à l’exploitation en production. Elle inclut les données, les modèles, les pipelines, les applications et les usages réels.
Elle est cruciale car les risques ne se concentrent pas sur un seul point. Ils émergent de l’ensemble du système. Sans approche globale, les vulnérabilités se multiplient et deviennent difficiles à maîtriser, en particulier à grande échelle.
Comment identifier les vulnérabilités et les risques liés à l’IA ?
L’identification des risques repose sur une combinaison d’analyses et de tests.
Il s’agit d’examiner les données, les modèles et les flux applicatifs, mais aussi d’observer les usages réels. Les tests de sécurité, les scénarios adversariaux et le threat modeling permettent de révéler des vulnérabilités souvent invisibles en phase de conception.
La surveillance des anomalies, notamment les tentatives d’injection ou les comportements atypiques, complète cette approche tout au long du cycle de vie.
Quelles pratiques de sécurité mettre en place pour le déploiement de l’IA ?
Le déploiement sécurisé repose sur quelques principes structurants.
Le contrôle des accès, la segmentation des environnements et la gestion des identités sont essentiels pour limiter la propagation des risques. À cela s’ajoutent des mécanismes d’observabilité, des tests continus et des procédures d’incident clairement définies.
L’objectif n’est pas d’ajouter des contrôles isolés, mais de construire un système cohérent, capable de fonctionner de manière fiable en production.
Comment garantir la sécurité et la confidentialité des données et des utilisateurs ?
La protection des données repose sur une combinaison de gouvernance et de contrôles techniques.
Il est nécessaire de classifier les données, de limiter leur exposition et de contrôler strictement les accès. L’anonymisation ou la minimisation des données permet de réduire les risques, mais ne remplace pas une gestion rigoureuse des usages.
La traçabilité des accès et des interactions est également déterminante pour détecter et comprendre les incidents.
Quels tests et contrôles sont recommandés pour protéger les modèles ?
La protection des modèles nécessite des tests réguliers et variés.
Les tests de sécurité, les attaques par injection, les évaluations de robustesse et les simulations adversariales permettent d’identifier les failles potentielles. Mais ces tests doivent aussi couvrir les sorties et les interactions avec les systèmes externes.
La détection d’anomalies et le suivi des performances complètent ce dispositif pour prévenir les dérives en production.
Qui doit être impliqué dans la sécurité de l’IA ?
La sécurité de l’IA est un sujet transversal.
Les équipes Data et Machine Learning, les experts en sécurité, les équipes opérationnelles et les métiers doivent travailler ensemble. Chacun apporte une partie de la vision, qu’il s’agisse de la conception, de la sécurisation, de la surveillance ou de l’usage.
Ce qui fait la différence, ce n’est pas seulement la présence de ces acteurs, mais la clarté de leurs responsabilités et leur capacité à collaborer efficacement.



.svg)
